bloggeek

Why you should prefer UDP over TCP for your WebRTC sessions
When using WebRTC you should always strive to send media over UDP instead of TCP. at least if you care about media quality
Every once in a while I bump into a person (or a company) that for some unknown reason made a decision to use TCP for its WebRTC sessions. By that I mean prioritizing TURN/TCP or ICE-TCP connections over everything else – many times even barring or ignoring the existence of UDP. The ensuing conversation is usually long and arduous – and not always productive I am afraid.
So I decided to write this article, to explain why for the most part, WebRTC over UDP is far superior to WebRTC over TCP.
Table of contents- UDP and TCP
- TCP rules the web
- UDP rules VoIP
- WebRTC ICE: Preferences and best effort
- When is TCP (or TLS) good for WebRTC media?
- When will TCP break as a media transport for WebRTC?
- Time to learn WebRTC
Since the dawn of time the internet, we had UDP and TCP as the underlying transport protocols that carry data across the network. While there are other transports, these are by far the most common ones.
And they are different from one another in every way.
UDP is the minimal must that a transport protocol can offer (you can get lower than that, but what would be the point?).
With UDP you get the ability to send data packets from one point to another over the network. There are no guarantees whatsoever:
- Your data packets might get “lost” along the way
- They might get reordered
- Or duplicated
No guarantees. Did I mention that part?
With TCP you get the ability to send a stream of data from one point to another over a “connection”. And it comes with everything:
- Guaranteed delivery of the data
- The data is received in the exact order that it is sent
- No duplication or other such crap
That guaranteed delivery requires the concept of retransmissions – what gets lost along the way needs to be retransmitted. More on that fact later on.
We end up with two extremes of the same continuum. But we need to choose one or the other.
TCP rules the webReading this page? You’re doin’ that over HTTPS.
HTTPS runs over a TLS connection (I know, there’s HTTP/3 but bear with me here).
And TLS is just TCP with security.
And if you are using a WebSocket instead, then that’s also TCP (or TLS if it is a secure WebSocket).
No escaping that fact, at least not until HTTP/3 becomes common place (which is slightly different than running on top of TCP, but that’s for another article).
Up until WebRTC came to our lives, everything you did inside a web browser was based on TCP in one way or another.
UDP rules VoIPVoIP or Voice over IP or Video over IP or Real Time Communications (RTC) or… well… WebRTC – that takes place over UDP.
Why? Because this whole thing around guaranteed delivery isn’t good for the health of something that needs to be real time.
Let’s assume a latency of 50 milliseconds in each direction over the network, which is rather good. This translates to a round trip time of 100 milliseconds.
If a packet is lost, then it will take us at least a 100 milliseconds until the one who sent that packet will know about that – anything lower than that won’t allow the receiver to complain. Usually, it will take a bit more than 100 milliseconds.
For VoIP, we are looking to lower the latency. Otherwise, the call will sound unnatural – people will overtalk each other (happens from time to time in long distance calls for example). Which means we can’t really wait for these retransmissions to take place.
Which is why VoIP, in general, and WebRTC in particular, chose to use UDP to send its media streams. The concept here is that waiting will cause a delay for the whole duration of the session reducing the experience altogether, while the need to deal with lost packets, trying to conceal that fact would cause minor issues for the most part.
With WebRTC, you want and PREFER to use UDP for media traffic over TCP or TLS.
WebRTC ICE: Preferences and best effortWe don’t always get what we want. Which is why sometimes our sessions won’t open with WebRTC over UDP. Not because we don’t want them to. But because they can’t. Something is blocking that alternative from us.
That something is called a firewall. One with nasty rules that… well… don’t allow UDP traffic. The reasons for that are varied:
- The smart IT person 30 years ago decided that UDP is bad and not used over the internet, so better to just block it
- Another IT person didn’t like people at work bittorrenting the latest shows on the corporate network, so he blocked UDP traffic of the encrypted kind (which is essentially how WebRTC media traffic looks like)
This means that you’ll be needing TCP or TLS to be able to connect your users on that WebRTC session.
But – and that’s a big BUT. You don’t always want to use TCP or TLS. Just when it is necessary. Which brings us to ICE.
ICE is a procedure that enables WebRTC to negotiate the best way to connect a session by conducting connectivity checks.
In broad strokes, we will be using this type of logic (or strive to do so):
The diagram above shows the type of preferences we’d have while negotiating a session with ICE.
- We’d love to use direct UDP
- If impossible then relay via a TURN/UDP server would be just fine
- Then direct TCP connection would be nice
- Otherwise relay via a TURN/TCP or a TURN/TLS server
UDP comes first.
When is TCP (or TLS) good for WebRTC media?The one and only reason to use TCP or TLS as your transport for WebRTC media is because UDP isn’t available.
There. Is. No. Other. Reason. Whatsoever.
And yes. It deserved a whole section of its own here so you don’t miss it.
TCP for me is a last resort for WebRTC. When all else fails
When will TCP break as a media transport for WebRTC?The moment you’ll have packet loss on the network, TCP will break. By breaking I don’t mean the connection will be lost, but the media quality you’ll experience will degrade a lot farther than what it would with UDP.
Packet loss due to congestion is going to be the worst. Why? Because it occurs due to a switch or router along the route of your data getting clogged and starting to throw packets it needs to handle.
Here are all the things that will go wrong at such a point:
- TCP will retransmit packets – since they weren’t acknowledged and are deemed lost
- Retransmitting them will take time. Time we don’t have
- For a video stream, in all likelihood, the packet loss will be translated to a request to a new I-frame
- So the sender will then generate a new I-frame, which is bigger than other frames
- This in turn will cause more data to be sent over the network
- And since the network is already congested… this will just worsen the situation
- Here’s the “nice” thing though. TCP is retransmitting the lost data
- So we now have data we don’t need being sent through the network
- Which is congested already. Causing more congestion. For things we’re not going to use anyways
- It is actually hurting our ability to send out that I-frame the receiver is trying to ask for
- We’re also running on top of TCP, so there’s no easy way for us to know that things are being lost and retransmitted since TCP is hiding all that important data
- So the moment we know about packet loss in WebRTC is way too later
- No ability to use logic like intra packets delay (that’s smart-talk for saying figuring out potential near-future congestion, which also feels like smart-talk)
- And no way to employ algorithms to correct congestion and packet loss scenarios quickly enough
Bottom line – TCP causes packet loss issues to worsen the situation a lot further than they are, with a lot less leeway on how to solve them than we have running on top of UDP.
The assumptions TCP makes over the data being sent are all wrong for real time communications requirements that we have in protocols like WebRTC
Time to learn WebRTCI’ve had my fair share of discussions lately with vendors who were working with WebRTC but didn’t have enough of an understanding of WebRTC. Often that ends up badly – with solutions that don’t work at all or seem to work until they hit the realities of real networks, real users and real devices.
I just completed a massive update to my Advanced WebRTC Architecture training course for developers. In this round, I also introduced a new lesson about bandwidth estimation in WebRTC.
Next week, we will start another round of office hours as part of the course, letting those taking this WebRTC training ask questions openly as well as join live lessons on top of all the recorded and written materials found in the course.
If you are planning to use WebRTC or even using WebRTC, there isn’t going to be any better timing to join than this week.
Learn more about my WebRTC trainingThe post Why you should prefer UDP over TCP for your WebRTC sessions appeared first on BlogGeek.me.
Why CPaaS is losing the innovation lead to UCaaS
It seems like CPaaS vendors have grown complacent compared to the rapid innovation coming from UCaaS vendors. This makes no sense.
CPaaS has been leading the innovation when it comes to how developers build communication products. This has been the case ever since CPaaS was coined. But now, the trend is changing. This is doubly true for WebRTC and video communication services. UCaaS vendors have taken the lead in innovation and setting the pace of the market, leaving CPaaS vendors behind.
Can this trend be reversed? Is this a bad omen for CPaaS vendors competing in video use cases?
Table of contents- Predicting future communication trends
- The promise of CPaaS
- Pandemic requirement shifts
- CPaaS during the pandemic
- UCaaS during the pandemic
- Pandemic valuations
- The differentiation dilemma & Build vs Buy
- Wake up and smell the coffee
I used to work at RADVISION. The company specialized in video conferencing equipment but was split into two business units. The one I was a part of licensed VoIP software stacks to developers. You could say that what we did predates CPaaS. We didn’t have the cloud or server APIs but we sure did have SDKs.
In each and every townhall the company had, the CEO used to mention that our business unit was a precursor of the industry. Whatever requirements we’ve seen, whatever trend we experienced in sales (increase or decrease) was just an indicator of what is to come in the market in 3 years or so. The reasoning was simple – we licensed to developers, which then built their products and put them to market. Development cycles being as they were, 3 years was a good estimate.
Fast forward to today, and you have CPaaS vendors (the technology licensors of communication development tools) and the rest of the industry. And the large part of the rest of the industry is UCaaS.
The thing is, UCaaS vendors are no longer waiting for CPaaS vendors to innovate – they are just doing it on their own.
The promise of CPaaSCommunication Platform as a Service. What is it for anyways?
The whole purpose of CPaaS is to reduce the time to market for developers. Make it easier to get things done with communications by developing all the nasty little details for you.
Call it low code. Call it SDK or API or whatever.
I did an interview with Jeff Lawson, CEO of Twilio years ago. There Jeff explains the essence of Twilio – why he started the company. And the reason is to solve the communication problem for companies so they can focus on building great customer experiences.
Remember this one. We will be back to this interview a wee bit later.
Pandemic requirement shiftsThen the pandemic hit. And with it, a change in what communication requirements looked like around the world for all use cases.
4 distinct changes took place:
#1 – meetings became largerWe had large meetings before. The difference was that we connected rooms with groups of people in each room. Now? Everyone’s joining from his own place.
A meeting with 20 people in 3 rooms became a meeting with 20 people from 20 rooms. We will be back in the office, but the requirement for bigger meetings, with more people joining remotely will still be there with us.
Look at the start of this session from last year’s Kranky Geek virtual event.
Here Li-Tal Mashiach, Senior Engineering Manager at Facebook in the Messenger team explains what they’ve seen as changes in the usage of video calls in Messenger. Look at around the 2:40 mark in that video.
#2 – more meetings for longer periods of timeThis one is obvious. Or is it?
Almost all vendors have seen a significant growth in both the number of video sessions conducted on their platforms as well the length of these sessions.
Scale had to be dealt with across these two axes.
You need to make sure you can carry conversations that now take hours on end instead of minutes:
- My daughter had 4+ hour long sessions with her friends during lockdowns going well into the night. They talked, are, cooked and did whatever the hell teenage girls do together – just remotely
- My son is still video calling with his cousin while playing Fortnite on his Xbox. And that usually lasts… well… until we stop them forcefully
In both cases, much of the interaction is just ambient video. They do things together or apart and just have these social interactions take place because they can’t meet. Funny enough, my son and his cousin aren’t stopping it now even though everything is open – that’s because meeting physically requires a 20 minute car ride…
How does that change the focus? How do you maintain servers, upgrade and update them when sessions can take hours on end on a machine? Does it mean the media servers also need to be stabler in how they operate?
And what about the number of sessions? Is it that easy to scale 10x or more your current traffic? This isn’t a simple question to contend with. Google shared their own challenges with scaling Meet which makes for a fascinating read. I had my share of vendors to help with best practices in scaling their WebRTC infrastructure during the last 15 months as well.
#3 – more networksBack to that Kranky Geek video by Facebook. They saw an increase in desktop access. More than they had expected being mobile first.
I’d argue that we’ve all seen more variety in devices and networks. My apartment went from 1 video calling user to 4 video calling users in a matter of a day. Billion people or more who never went on a video call have done so and will continue to do so at least some of the time.
What devices do these billion people have? What does their home network look like?
If you look at the technology adoption curve, these aren’t the innovators or early adopters. They aren’t even the early majority. They include both the late majority and the laggards.
This means we’re facing a lot more variance in devices and networks. In the need to deal with lower end capabilities and resources available. And to deal with having these large groups take place with a larger variety of the differences across devices.
#4 – more placesThe best part of video calling during the lockdowns and up until today is taking a peak at other people’s home office. You get to see a piece of who they really are outside “work”.
These places are almost always less than ideal.
- Dogs and cats being part of the background
- Kids. Lots of kids. Popping into the screen. Making noise
- People walking in the back doing laundry, cooking, running after kids. The works
- Construction noises from outside
- Poor lighting conditions
Everything you can think of that affects the audio and video quality due to external sources will be there. And you can’t always ask the user to go purchase a better camera, change where he is sitting or replace his device.
It becomes a technical problem to solve many of these issues, especially when the service offers ad-hoc connectivity for its users.
CPaaS during the pandemicCPaaS were supposed to help vendors build their products. Look at future needs and cater for them. And for the most part they do. But somehow during this pandemic, it seems that many of them have failed to do so.
I’ll look at Twilio here – and not because they are the only vendor with these issues – but because they are the biggest CPaaS vendor and the precursor of the industry.
Last year after Twilio’s Signal 2020 event I wrote that I expected more of them:
For me this says that Twilio hasn’t invested in video as much in the last year or two. If they had, they would have announced something more thrilling and interesting. Maybe larger meetings, above 50 participants? Broadcasting capabilities? Noise suppression? Something…
Since I wrote that, 8 months have passed. Meeting sizes for Twilio Programmable Video are still limited to 50 participants. There are no broadcasting capabilities. No noise suppression. No background blurring. Nothing.
I can’t even recall any real additional feature that Twilio introduced for Twilio Programmable Video since that Signal event. Maybe updates and improvements to their React reference app, but nothing more.
Most other vendors showed similar inclination and introduction of new features throughout the pandemic. It seems like the trend now for video APIs is to focus on embedded iframes for faster development. These have been discussed and experimented with years ago, and now seem to be finding new traction and interest.
It takes more time to develop features in CPaaS than it does on other platforms. The reason for that is the CPaaS vendors need to do 2 things others don’t have to deal with:
- Make the feature generic, solving a problem for more than a single use case or customer
- Document the feature properly, so that developers will be able to figure out how to use it
But let’s face it. These new requirements have been around for 15 months now…
There are obviously a few caveats here:
I am griping here about video
CPaaS has grown during the pandemic, so this hasn’t hurt them. Yet
Video is usually a small percentage of traffic and income for a CPaaS vendor
UCaaS during the pandemicUCaaS shows a stark contrast to how CPaaS responded.
Many of the leading vendors have added background blurring and replacement, noise suppression and other features and capabilities. They have done so in breakneck speeds and they seem to be spewing out new features every week or so.
This isn’t limited to a single vendor. Out of the top of my head: Zoom, Microsoft Teams, WebEx, Google Meet and RingCentral all introduced these features in the past year. And all of them seem to be investing further into these areas while pushing forward other initiatives they have, each with its own focus.
Remember Jeff’s interview? I asked him if he believed UC vendors should develop their services on top of CPaaS. This is what he answered:
Yeah. I believe that companies whose primary business is communications can and definitely should and would get competitive advantage by using a platform like Twilio to build upon. The reason why is this. It used to be when those UC companies started, their core competency was making the phone ring. Then they’d add some software functionality on top of it, sure, but the vast majority of what they worried about was how do I make the phone ring? The problem is Twilio has democratized that ability.
[…]
The existing UCaaS vendors, they would be wise to build on top of the same platform that any developer in the world can come and start to compete with them on. If they don’t, those independent software developers, they can actually start and build companies that are really compelling competitors, because they don’t have to focus on the low level bits. They’re focused on the things customers really care about, which is features, functionality, and the user experience that matters.
While mostly true, this doesn’t hold water these days for video communications. Relying on CPaaS vendors means you need to figure out the feature set that is necessary to be a compelling competitor yourself – larger groups, background replacement, noise suppression, …
CPaaS vendors need to put their act together in the video domain, or start losing customers that will just go build this on their own. Especially when we see Zoom coming up with their Video SDK and becoming a direct competitor to CPaaS vendors.
UCaaS vendors are having their own headaches in the market due to the dramatic changes that Microsoft and Google are bringing into this domain. I’ll leave that for a future article.
Pandemic valuationsThe pandemic also changed the dynamics in communication vendor valuations, shifting the focus to slightly different domains.
Hopin and Clubhouse, which I already touched on in my previous article about the new era in WebRTC.
Agora (video CPaaS vendor) had a hugely successful IPO, followed by another spike due to the popularity of Clubhouse (who is using them). They are now back to roughly their initial IPO price point.
Twilio (CPaaS) increased in their valuation throughout the pandemic. My guess is that this is mostly due to the increased use in voice and SMS. Less so in video, where they invest a lot less.
Zoom. Need I say more?
The differentiation dilemma & Build vs BuyHow does one differentiate then?
- CPaaS vendors haven’t done enough during the pandemic to enable differentiation for the video use cases
- The same CPaaS vendors also haven’t differentiated enough from one another – at least not on the surface level
- Build on top of your CPaaS vendor the missing features (if possible)
- Build your infrastructure in-house
I am seeing the following trends in CPaaS adoption and use. They used to be related to pricing, but now they are becoming more and more related to feature sets and differentiation needs:
Most enterprises stick with the use of CPaaS vendors. They rely on them for their communication needs. They will switch from a CPaaS vendor to another CPaaS vendor if they can get better pricing or if their current vendor is lacking features (or provides poor support).
Technology vendors and startups will pick either CPaaS vendors as their starting point or prefer going it alone from the get go. Those that become hugely successful will end up actively working on replacing the CPaaS vendor with their own infrastructure. They will see that as an imperative a lot more than their enterprise brethrens.
Unified communication vendors will continue as they are. Assuming that communication infrastructure is core to their business and will work towards maintaining their own knowledge and experience in the area – doubly so after the pandemic.
Wake up and smell the coffeeCPaaS vendors should wake up and smell the coffee.
The world has changed. Drastically.
There’s no going back to the old ways – even without quarantines.
I believe that there’s a competitive advantage waiting here. CPaaS vendors have been shying away from these requirements. The first ones to come out with actual solutions and feature capabilities that will ease the development of customers will win due to this differentiation.
The reason this hasn’t happened so far is that traditionally, such things weren’t catered for directly by CPaaS vendors – it is out of their comfort zone. This leads to an opportunity that is up for the taking.
—
On a similar note, after running successfully the Future of Communications workshop with Dean Bubley, we decided that it is both information packed and fun to do. If you are interested in a private session for your company – let us know.
The post Why CPaaS is losing the innovation lead to UCaaS appeared first on BlogGeek.me.
WebRTC: The end of an era (and the dawn of a new one)
After 10 years, we are at the dawn of a new era for WebRTC. This one is going to focus on differentiation and will bring with it new dominant players into the field.
There’s a change in the air. I think it started towards the end of 2019, but now it is quite obvious to see. WebRTC is changing – not the specification but rather who is using it and how it is used.
Table of contents- A look at the history of WebRTC
- WebRTC 1.0
- The pandemic
- Zoom
- WebRTC musical chairs
- WebRTC “winners” of 2021
- Welcome to the new WebRTC
There’s a slide I showed last week in the workshop of the future of video and real-time communications. It resonated with me with the latest news of Justin Uberti leaving Google. So much so, that I decided to record it separately and share it here as well:
We’ve moved from exploration to growth and now into differentiation when it comes to WebRTC.
What got us there exactly?
WebRTC 1.0We’ve got that WebRTC 1.0 milestone behind us now.
I haven’t written any special article about WebRTC 1.0, because the main question you need to ask yourself is what changed?
And the real answer is nothing.
The work towards WebRTC 1.0 was important and this is an important milestone. But browser vendors already implemented WebRTC. And vendors already used WebRTC in browsers and native applications as if this was a done deal already.
If you were using WebRTC before, then nothing has changed for you since the announcement of WebRTC 1.0.
And if you haven’t used WebRTC yet, then why start now? What was holding you back so long? The fact that you weren’t sure if it is here to stay???
Having WebRTC 1.0 out is an important milestone. More a symbol and a signpost than anything else.
The pandemic The pandemic had a positive effect on WebRTC adoptionThe pandemic got us all quarantined and changed everything.
There’s no new normal to talk about yet, but if you’re believing things are “going back to normal” then you’re wrong.
To put simply:
- More businesses than ever before are just “fine” with employees working from home (or remotely)
- Some businesses are fine doing that ALL the time, permanently
- Other businesses are just as happy if you come to the office only some of the days of the week
- More employees want to work remotely
- Some employees simply don’t want to go back to the office. They’re just fine working from home. They will actively seek such jobs
- Other employees are fine working a few days in the office and the rest remotely, so they don’t have to commute as much while still socializing face to face with their peers
- ALL businesses want to sell more. They couldn’t care less if their clients are buying stuff locally or remotely
- More customers are now fine with purchasing remotely or even being served remotely
These changes are bringing with them a lot of new demand, new use cases and new requirements.
What we focused on with WebRTC up until 2020 was suitable for the “old” pre-pandemic world. What we need to focus on now is on the “new” post-pandemic world, one which has slightly different requirements.
Zoom Is Zoom the exception to prove the rule?Even before the pandemic, Zoom’s IPO has been phenomenal.
After the pandemic, Zoom has become a household name.
Pick any communication service you wish from any vendor in the globe. Randomly pick 100 people from the world’s population. How many of them will know that vendor or service, and how many of them will know Zoom?
Zoom doesn’t really use WebRTC, so why should you?
This is an important question. The appropriate answer is probably one of context. Your context is different from Zoom’s.
- Using proprietary real-time video is a hard problem to solve, so why not use WebRTC instead of solving it yourself?
- Nobody knows you yet, so whatever Zoom has going for it might not necessarily fit your situation
- Zoom is probably installed on most machines today. Your app isn’t. How will you entice potential users to download and install your app?
And yet the WebRTC industry, its stack, the browsers and vendors are consistently being compared to Zoom.
Your ability to compete with Zoom on quality and connectivity is greatly dependent on Google, and what they decide to do with WebRTC.
You are not in full control over your destiny.
WebRTC musical chairsThere were a few changes in the people who are working and dealing with WebRTC directly recently. I want to discuss 3 specific cases that I think mark the end of an era.
Dr Alex Gouaillard, CoSMo and MillicastDr Alex Gouaillard passed away in April 2021.
Alex has been a known figure in the WebRTC community. His voice on subjects, his passion and his work has made its mark on our industry. He will be sorely missed.
In recent years, Alex focused heavily in the area of live streaming, trying to solve the challenge of broadcasting a WebRTC stream to many participants. He has been a vocal proponent of the use of AV1.
It will be interesting to see who will pick the mantle here and fill the void in explaining and promoting these use cases now.
Nils Ohlmeier, Mozilla (now 8×8)Nils Ohlmeier has been “the guy” from Mozilla who represented WebRTC in Firefox.
He shared the work Mozilla is doing in Firefox for WebRTC in last year’s virtual Kranky Geek event as part of the browsers panel we did:
Nils switched employers this month, starting to work at 8×8 in the role of Principal Engineer. He will be contributing to the Jitsi codebase and its growth. While Jitsi has a large and vibrant ecosystem, is it anywhere near the size and complexity Mozilla had to deal with?
Who is going to take this role at Mozilla?
Is Firefox interesting as a browser for WebRTC developers and users anymore?
Was it time to move on now that the biggest challenges of WebRTC for browser vendors is “behind” us?
To me, these questions more than anything else mark the change in times.
Justin Uberti, Google Stadia (now Clubhouse)Justin Uberti was there from the start when it came to WebRTC.
He is considered by many the lead engineer behind the Google Chrome team of WebRTC, and he was part of the original duo (not only the app) – Serge Lachapelle & Justin Uberti.
Justin moved on from the WebRTC team to Google Stadia at the end of 2019. He worked on Stadia related features before that as well.
This month, he decided to move on, leaving Google altogether, pursuing new activities. Justin is staying in the WebRTC industry, as his new role is Head of Streaming Technology at Clubhouse.
Here’s what Justin had to say at Kranky Geek 2018 during Google’s WebRTC update session:
It is truer today than it was in 2018…
Definitely the end of an era.
WebRTC “winners” of 2021In 2017 I’ve written about 10 Massive Applications Using WebRTC.
That was 3.5 years ago and before anyone thought about quarantines or Zoom.
Fast forward to today, and that list is going to look different.
Two vendors I want to highlight here are Hopin and Clubhouse. They are different from the other vendors we’ve seen in the past who are making use of WebRTC.
HopinHopin is a virtual events platform founded in June 2019, a bit less than two years ago. They couldn’t ask for a better timing (maybe start 6 months earlier?).
Within that timespan, Hopin managed to raise a whopping $571.4M in total and made 4 acquisitions (including StreamYard, Streamable and Jamm).
There are many virtual events platforms ever since the pandemic started but Hopin seems to be the biggest and most widely known one. They have shown that they aren’t shy of acquiring the technologies they need in order to get their feature set where they want it to be.
In 2019, who would have thought a virtual events vendor would be worth $5.65B in valuation by 2021?
Hopin has a nice warchest that they can use to grow their business, attract top notch developers and acquire or acquihire their way to success.
ClubhouseAnother interesting vendor is definitely Clubhouse.
Everyone wants to be Clubhouse these days, but there’s still only a single Clubhouse out there.
Clubhouse started life with the pandemic, in March 2020. After only 14 months it has a valuation of $4B and has been funded well over $100M ($110M by series B in January this year, and another undisclosed series C in April). That’s quite a feat for a voice only, iOS only (until recently) service.
It has a warchest to rival that of Hopin and the same kind of hype behind it to allow it to do practically anything it wanted.
Clubhouse still lacks a real business case, but it doesn’t seem to be stopping it.
Clubhouse is known to be using Agora as their CPaaS vendor, but that may soon change. They hired Justin Uberti from Google, and the only reason for that to me seems to be the desire to own and control their infrastructure.
GoogleGoogle is still the big winner of WebRTC.
If you look at what features are added to WebRTC, then the answer to that is whatever Google needs for its own uses.
These uses now include Google Meet, Google Stadia and Google Assistant.
If your use case has the same requirements in general then you’re in good shape. If you are going “off the reservation”, then prepare for a life of misery if there’s something missing that you need and isn’t in Google’s own set of requirements.
WebRTC is open source up to a point. Not because the code isn’t open and available to all, but because the main implementation is owned and controlled by Google and the main browser you’ll need to work with is Chrome.
Welcome to the new WebRTCFrom now on, WebRTC is going to be different.
Talking heads are still an important part of it, but the focus is shifting from a “video chat” or “video conferencing” service into a communication service that is unique. What that is exactly is hard to say, but suffice to say that WebRTC is there in the background.
And fading to the background is exactly what we wanted from WebRTC – the technology is only great once we start forgetting it is there.
The post WebRTC: The end of an era (and the dawn of a new one) appeared first on BlogGeek.me.
Interoperability and standardization in a world dominated by WebRTC & Zoom
Rethink the way we look at interoperability and standardization in communications, now that we live in a WebRTC & Zoom world.
We live in a different world. This video popped up in my Facebook as something I shared a year ago:
It is in Hebrew, but there are enough words in English there to make it quite apparent. This comedian is trying to explain to his mother over the phone how to use Zoom.
Today? Everyone knows how to use Zoom. Or WebRTC.
The transformation of communication technology- Rewind 20+ years ago
- The rise of the smartphone (and the cloud)
- A new way to look at communication standards: WebRTC
- Zoom and the pandemic
- Workshop: The Future of Video & Realtime Communications
I started my professional adult life in a video conferencing company. There, I lived and breathed interoperability and standards for the better part of 13 years. I have a few contributions that got approved at the ITU and 3GPP. I’ve been to interoperability events and even hosted two of those in Israel.
At the time, the mindset was a telephony one:
- There is a single way of doing things. We call that the standard specification
- Vendors can implement different components of that specification
- A buyer can purchase any component from any vendor and miraculously, his new purchase would “speak” to all other components on the network
- Why? Because they are all interoperable. Per the standard
There were two main reasons why we wanted such a world to live in:
- Lower the barrier of entry. For a single company to develop it all requires huge budgets. Smaller vendors couldn’t take that risk and we wanted the innovation
- Monopoly power and vendor lock in. We wanted to give clients choice in what they purchased and have the ability for them to mix and match and not be locked in to a specific vendor for life
Then Apple came with the iPhone and changed. Everything.
From embedded platforms, the smartphones became open programming platforms (open even within the closed gardens of their app stores).
Today, many of the embedded devices include an Android operating system, making it ever easier to develop software for them.
This brought with it a new kind of openness:
- You didn’t have to purchase a device that adhered to a standard specification
- The alternative was to download or install the necessary communication software instead
This didn’t mean standards were unimportant. It meant that interoperability became less interesting. Vendors could now bake their own proprietary additions on top of the standards that give extra features without the need to think too much about interoperability with other vendors – that’s because your client now brings his own device (BYOD) and you supply the software application to connect to the infrastructure.
Oh, and by the way – that infrastructure? It is now built in the cloud. And the cloud enables rapid development and hyper growth. Which again means that caring about interoperability becomes less of an issue between the client device and the cloud infrastructure – vendors are more interested in interoperability between their infrastructure components or with external service providers – via gateways.
This turned communications from a service into just another application on our phones.
A new way to look at communication standards: WebRTC WebRTC brought communications to the browser, making it into a feature{kind=link}
WebRTC came to our world about 10 years ago and changed the paradigm again.
Where the smartphone and the cloud reduced our dependency and need for interoperability, WebRTC reduced our dependency and need for standardization.
We still need standardization – after all, WebRTC is a standard.
But the standardization we care about is mostly the browser implementations versus the specification (and interoperability between browsers). Other than that? We couldn’t care less.
The client side is no longer even a software application. It is a bunch of JavaScript lines of code that get executed inside a web browser that supports WebRTC. We can still do applications, and we do, but the concept and the intent is the same – standardization across vendor’s components and devices is now overrated and mostly unnecessary.
If we need standardization and interoperability, we let gateways do it. As we did in the era of the smartphone.
WebRTC also made communications more accessible. Web developers could now use it, and you could easily embed and stitch it right into your application as a seamless part of your business process flow.
This turned communications from a service or an application into a feature in another service or application.
Zoom and the pandemic The pandemic made video communication commonplace, enabling Zoom to turn it into a platformThen the pandemic came and made a world a lot smaller. It made sure we all know how to use video communications.
Zoom became a household name across the globe and turned into a noun.
Zoom is proprietary. It doesn’t even use WebRTC.
No standards. Which lead to a lot of security missteps.
But it worked. And now Zoom has a Client SDK a Video SDK and Zoom Apps. With the intent of making their infrastructure and technology integratable with anything and everything.
This is an attempt to turn communications from a service or an application or a feature into… a platform.
Workshop: The Future of Video & Realtime CommunicationsA few weeks ago, I had a conversation with Dean Bubley. We wanted to do something together, and decided to create a joint workshop.
The question of the role of standardization and interoperability is one of those we are going to tackle in the upcoming workshop.
If you are interested in joining the workshop, register below. There’s an early bird discount that is available only until the end of this month.
REGISTER TO THE WORKSHOPThe post Interoperability and standardization in a world dominated by WebRTC & Zoom appeared first on BlogGeek.me.
Lyra, Satin and the future of voice codecs in WebRTC
There are new audio codecs in town: Google Lyra and Microsoft Satin. Both banking on AI-based voice coding, and both will be fighting for inclusion in WebRTC.
{kind=link}
Right on the heels of the changes we see in video codecs in WebRTC, with AV1 coming into the stage, and HEVC making an entrance in Apple devices, we now have a similar (?) story with voice codecs. Microsoft announced its AI-powered voice codec Satin in February. A week later, Google reciprocated in kind, announcing its low bitrate codec for speech compression Lyra.
Why now? What are the similarities and differences between these codecs? Where are they headed? And what does that mean to WebRTC and to you?
Table of contents- Audio codecs in WebRTC
- The two extremes in audio codecs: Low bitrate vs lossless
- AI and audio codec generations
- The Opus spec
- Microsoft Satin
- Google Lyra
- A multi-codec audio future for WebRTC?
- FAQ on Satin and Lyra
It makes sense to start this by explaining a bit about audio codecs in WebRTC.
WebRTC has mandatory to implement codecs. For audio/voice, these codecs are G.711 and Opus.
For all intent and purposes G.711 is there as a legacy codec, to deal with narrowband audio. The result of which is low quality, unresilient audio. Using G.711 is mostly reserved to connect it with the telephony networks, and even there, I wouldn’t recommend it as a solution.
Opus is the main voice codec in WebRTC. It offers a highly flexible solution capable of handling anything from narrowband to fullband stereo and at low bitrates. You can read more in this article I’ve written years ago: The Rise of Opus to HD Voice Domination.
Opus is almost 10 years old. It has been created by meshing two separate codecs: SILK (for speech) and CELT (for music). The pandemic of 2020, and the increased reliance on virtual meetings has started to show its age and its limitations. Opus is a great codec, but these days, we can probably do better.
How Opus works, from my Advanced WebRTC Architecture Course The two extremes in audio codecs: Low bitrate vs lossless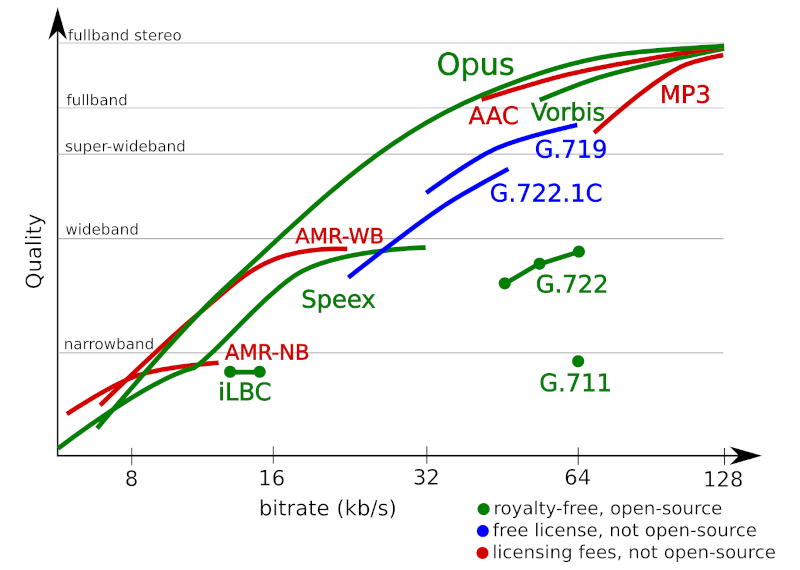{kind=link}
So what are the missing pieces? The things that Opus can’t get done on its own? There are two such areas that are actively being explored, and they are two extremes: highest possible audio quality and lowest possible bitrate.
Highest possible quality: Lossless audio codingOne extreme (unrelated to Lyra and Satin), is the strive for the highest possible audio quality. Getting there requires the use of lossless audio coding.
For all intent and purpose, what we do in VoIP today, and by extension in WebRTC, is use lossy coding. This means that we compress the audio and video in ways that don’t really allow us to reconstruct the original audio or video accurately, but instead it gets us “close enough” to there. It does that by trying to “get rid” only of information that we humans can’t discern – things the human eye and human ear would miss anyways.
As a crude example, I never did hear the difference between vinyl, cassettes and CDs – at least not enough for it to matter for me. On the other hand, I had a friend who complained that CDs don’t have the audio quality of vinyl records.
The most known lossless audio codec is FLAC. It has nothing to do with WebRTC. Yet.
Lowest possible bitrate: AI based compression{kind=link}
In the other end of this spectrum lies the lowest possible bitrate we can comfortably reach.
It turns out that Opus is good, but not great.
At a time where bandwidths are increasing, why do we even discuss getting voice codecs into lower and lower bitrates? What would be the incentive?
These questions are doubly important considering the fact that we’re heading towards a remote video filled world. And we know that video takes up considerably more bitrate than voice, so why care so much about voice bitrates?
One reason is simply the fact that we’re now communicating remotely a lot more. We do that more, and there are also a lot more people communicating online. From everywhere. This means that not all of them are going to be on great networks at all times, and even when they are, others are going to strain these networks with their own traffic. Google calls this “the next billion” – the next billion people joining the internet, which means people with less means and by extension less bandwidth.
The other reason is the fact that we’re growing bigger. More sessions. Bigger sessions. Widely spread. If we can even reduce a fraction of the bitrate, that would reduce the strain on our networks, servers and costs of running services.
I am also guessing that the big video meeting vendors got to learn a few interesting things during the pandemic. One of them is that voice is the most important part of a video call. If you don’t deliver your voice properly, video won’t matter. And for that, you need to make it leaner and meaner than it is today.
{kind=link}
How do you make voice compression for an audio codec better?
AI and audio codec generationsI’ll be using machine learning (ML) and artificial intelligence (AI) interchangeably here. These terms have been butchered by marketers so much, that they are now indistinguishable anyway.
Better in the case of audio codecs is going to be a new generation of codecs. In a way, a migration from the old way of doing things (rule engines and heuristics) to our brave new world of machine learning and artificial intelligence.
Machine learning is where the future lies when it comes to most of our algorithms. Especially with the ones that make extensive use today of either rule engines or heuristics – both of which are found in abundance in real time media processing pipelines (=WebRTC). We started seeing this trend seeping into real time communications and WebRTC somewhere in 2018. After the initial hype, we found out the many challenges of adding machine learning. In 2020, it seemed like the path became somewhat clearer: noise suppression and background replacement solutions assisted with AI. For the rest? We understood collectively that we should first squeeze the lemon of optimization before resorting to AI.
It is now time to look at AI in media compression as well. We’ve seen this take place already in baby steps. At Kranky Geek 2019, Shawn Zhong of Agora, explained how AI can be used to improve encoding efficiency:
A year later, NVIDIA introduced Maxine, a platform capable of using AI to “reconstruct” a person. Effectively creating a kind of a compression algorithm.
Research around AI compression is flourishing. There is already an AI specific standards organization called MPAI (Moving Picture, Audio and Data Coding by Artificial Intelligence) – still small, but this may change in the future. And then there’s Mozilla’s Common Voice, an open source, high quality, labeled multi-language dataset for training language related models.
{kind=link}
It makes sense then, that audio would be a prime target for AI based compression as well. Here, Microsoft took the first public shot, and Google immediately followed suit.
The Opus specTo understand where Microsoft Satin and Google Lyra are headed, let’s first review how Opus works:
- Opus has a range of 6-510 kbps of compression
- Realistically, for WebRTC, it would be 6-40kbps, and in most cases ~26-30kbps
- It runs the gamut of narrow band up to full-band stereo
- Latency of 26.5ms, making it quite powerful for real time since it adds very little inherent delay of its own
- As mentioned above, for speech, Opus uses a modified SILK implementation. For music it uses CELT, another audio codec. It can use them simultaneously as needed. And interestingly enough, it has a small machine learning model that decides what to use by classifying the audio input as either speech or noise
Now let’s look at what we know so far about the two new audio codecs.
Microsoft SatinMicrosoft Satin is being positioned as an AI-powered audio codec to replace Silk.
Silk is used by Skype and was adopted as the basis for Opus as well. Here’s what Satin can do based on Microsoft’s announcement:
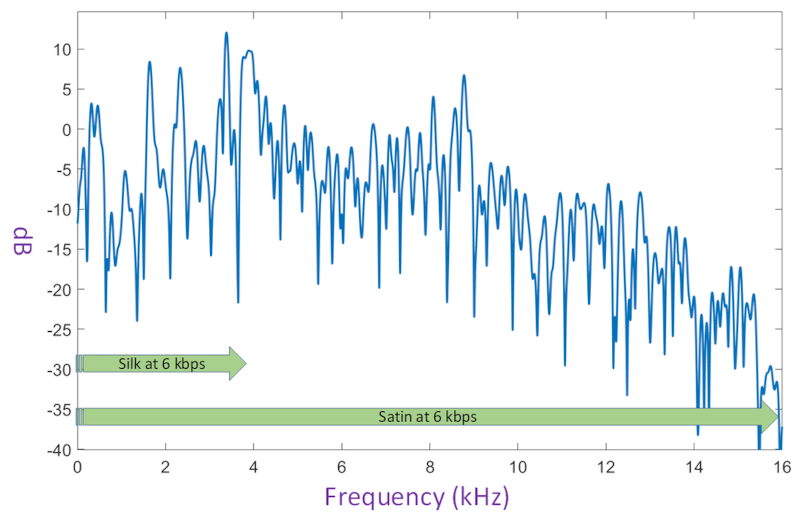
- Super wideband speech starting at a bitrate of 6 kbps
- Full-band stereo music starting at a bitrate of 17 kbps
- Progressively higher quality at higher bitrates
- Provide great audio quality even under high packet loss
- Better redundancy algorithms to provide better protection under burst loss
{kind=link}
Satin wasn’t presented as a work in progress, but rather as a battle tested codec – Microsoft stated it is already being used by Microsoft Teams and Skype in 2-way calls. Obviously, with plans to extend it to group calls.
Satin is a brand new codec that is being designed to replace Opus altogether.
Google Lyra{kind=link}
Google’s announcement of Lyra came a week after Microsoft’s. In a way, it seemed a bit rushed.
Why rushed? Because of how the announcement is written. It reads similar enough to the Microsoft one but lacks the “currently deployed” paragraph. Instead it has a “currently rolling out” paragraph.
What is Lyra about? Based on Google’s announcement:
- Very low-bitrate speech codec
- Processing latency of 90ms (on the slow end of the spectrum of real-time voice codecs)
- Designed to operate at 3kbps
- Currently optimized for the 64-bit ARM android platform
{kind=link}
Lyra is intended for SPEECH and not for AUDIO. It isn’t a replacement of Opus in any way.
Interestingly, Google believes that coupled with AV1, it can offer decent video conferencing experience at dial-in modem bitrates of 56kbps.
Lyra is being rolled out to Google Duo for very low bandwidth connections scenarios. But that’s about it for the time being.
More recently, Lyra has been open sourced by Google. The reasons for this are varied, especially considering that many of the recent advancements of Google in AI around real time communications weren’t open sourced at all:
- Lyra came after Satin. They will both be fighting it out on being included in WebRTC
- It is superior to Satin (probably) at the very low bitrate of 3kbps, especially considering Satin was designed for 6kbps and above. But it is no match to Satin in higher bitrates, where Satin most probably beats Opus
- Google decided long ago that codecs should be free and open source (see the WebM project). As such, Lyra needs to play by these rules as well. Google might not see a competitive advantage here and would rather have this available across the board
Another thing you can achieve with Lyra is better redundancy for improved resiliency. With its very low bitrate, it is less of a constraint to add redundancy on top of it. You can check out this article on webrtcHacks by Philipp about audio redundancy encoding.
A multi-codec audio future for WebRTC?At the moment, both Lyra and Satin are nice bedtime stories. You can use them only inside the proprietary implementations of Google and Microsoft. And even then, in most cases you wouldn’t even know that to be the case.
Why was it important then to announce these efforts?
My hunch is that it has to do with standardization and WebRTC.
WebRTC needs some love and attention now in the audio front. For video, we’re going to have AV1, but what do we do about voice?
There are currently two alternatives out there that will make their move soon enough:
- Satin. As a 3rd optional codec in WebRTC. Microsoft will need Google’s approval/help to push this one forward by making it a part of Chrome, otherwise, it won’t gain enough popularity and will be kept proprietary and niche
- Lyra. This codec makes no sense to me as a standalone codec. Adding it to WebRTC “as is” will be quite challenging for developers to make use of. There are a few routes that can be taken here:
- Have it handle wideband and full-band better and in a way competitive to Opus and call it a day. That means competing head-to-head with Satin
- Shove it into Opus. Call it Opus 2.0. Opus already contains SILK and CELT. Why not LYRA as well? Let Opus decide which one to use when and be done with it. Since Lyra is already open sourced, that can be a natural next step…
- Get Google and Microsoft in the same room and see how to put Lyra inside Satin, find a 3rd name for it so no one gets pissed off that the other won the marketing game, and add that new codec into WebRTC
It is too early to say how this will play out. My bet is on more optional audio codecs finding their way into WebRTC – not the boring old ones, but rather the hip new ones. This will make audio codec selection for developers building services a wee bit harder, which isn’t a good thing in the long run. I’d rather see this pushed into Opus – or added as a single codec replacement to Opus. Something that would be easy to pick instead of Opus.
FAQ on Satin and Lyra ✅ Is Google Lyra equivalent to Microsoft Satin?No.
While both of these audio codecs operate at low bitrates and are powered by AI they are very different. Lyra is focused on narrowband only while Satin is about operating in super wideband.
Technically – yes.
Microsoft is already using Satin instead of Opus in Microsoft Teams and Skype for 1:1 calls. IT was designed with that goal in mind.
No.
Lyra was designed to work at low bitrates where Opus doesn’t do a good job today. When there’s enough bitrate, Opus offers better audio quality than Lyra.
No.
There are no public plans to add either of these codecs to the WebRTC specification or to browser implementations.
The post Lyra, Satin and the future of voice codecs in WebRTC appeared first on BlogGeek.me.
🎲 Which video codec to use in your WebRTC application? 🎲
Picking the right video codec for a WebRTC application is tricky. Should you use VP8? H.264? VP9? Go with AV1? What about HEVC?
Table of contents- WebRTC video codecs – a quick reminder
- Video codecs support across WebRTC browsers
- Video codec performance in WebRTC
- Welcome to a multi codec WebRTC world
- WebRTC trends in 2021
WebRTC was once easy. You had VP8, Opus and G.711. G.711 is striked through because I don’t want you to use it. There’s really no reason to. Later on, H.264 was added as a mandatory to implement video codec. And all was well in the world of WebRTC.
Google then decided to introduce VP9 in Chrome. As an optional codec. Mozilla added VP9 to Firefox as well. Microsoft? They got it for “free” when they switched Edge to Chromium. And Apple… well… Apple. VP9 should be in their Technology Preview for Safari, but mainly because of Google Standia which uses VP9 – surprising as this may sound.
Oh, and Apple decided to add HEVC as an optional codec of their own to WebRTC – just for good measures. And to confuse us all even further.
Then there’s AV1. The next gen bestest video codec. For the time being. At least once it gets added to Chrome (in version 90 that is). And used by developers.
Video codecs support across WebRTC browsersThe diagram below is taken from my recent workshop on trends in WebRTC for 2021. It shows the current state of video codec support in web browsers.
To sum things up:
- VP8 and H.264 are ubiquitous across browsers, and yes, there are some issues with both of them
- VP9 isn’t adopted as much after years of being available to developers, and is coming to Safari “soon”
- HEVC is Apple
- AV1 is new
Last week, I sat down with Philipp Hancke for our WebRTC Fiddle of the Month. In this month’s fiddle, Philipp suggested we look at video codec performance, so he wrote a… fiddle.
You can watch the whole fiddle here: measuring video codecs performance
The results were quite interesting and sometimes surprising. What’s nice here is that you don’t need to take our word for it – you can take the code and use it yourself. Also make sure to use it in the scenario you have and not the simple one we’ve shared, as your mileage may vary.
VP8 or H.264 for your WebRTC application?Today? You’re probably using VP8 or H.264 – or should use VP8 or H.264.
Is there any real difference between the two? No. Not really. They produce similar video quality for a given bitrate.
That said, there are some nuances between them:
- Google doesn’t really use H.264 in WebRTC. So VP8 is the more maintained video codec out of the two. For example, H.264 didn’t support simulcast in Chrome for many years (it does now)
- VP8 has virtually no hardware acceleration, so it will eat up more CPU in some cases
- H.264 has hardware acceleration. On Apple devices. Sometimes on PCs. Sometimes on Android. Sometimes though, you won’t have a H.264 implementation in WebRTC, because the hardware isn’t accessible and the software implementation isn’t there (royalties and stuff)
- Temporal scalability is only available in VP8. Not in H.264
Our own quick tests suggest that the H.264 decoder is better than the VP8 one – with or without hardware acceleration on H.264. Definitely something to think about.
Which one should you use? Throw a dice… 🎲 or two 🎲🎲
VP8/H.264 or VP9 in WebRTC?Here’s a real question. Should you go for VP9? Last year I suggested it might be time to use VP9. Little has changed – no real adoption that I can see to it.
Except from Google, no one uses it.
In our tests, it was close to VP8 in its CPU use. That was quite surprising. It is probably why Google is using it in Google Meet.
The best thing about VP9? It also supports SVC (in an undocumented munging kind of a way).
The challenge? Apple. Doesn’t really have it yet. Should be getting there. Question is when.
When to use HEVC in WebRTC?This one is simple enough to answer – never.
That said, if you have calls that take place only between Apple devices, then HEVC might be a good option.
Is the time right for AV1?No. Maybe. Yes.
From our own testing, AV1 is considerably worse than all other codecs when it comes to performance. It takes twice or more of the CPU it takes to encode and decode any of the other video codecs we tried.
AV1 should offer better quality than the other codecs, so you may actually want to pay that extra CPU. As far as I can say, there are two reasons for using AV1 today:
- To handle specific scenarios such as very low bitrate, where CPU isn’t the bottleneck but bandwidth is
- When you are decoding only and the encoder is in the cloud – a place where you control the hardware. You’ll pay for it in compute costs though
- It is rumored to be good at decoding thumbnails
WebRTC started without many options. VP8 and H.264. That’s about it. Now? We’ve got 4-5 video codecs to choose from.
Most of us end up using VP8 just because. Some pick H.264, mainly because of performance considerations. The rest are mostly talked about but almost never used.
The newer video codecs are really promising – VP9, AV1 and even HEVC have real potential in a WebRTC application. The challenge though as that they come with some big challenges – mainly CPU and availability across browsers.
To use them, a new approach is needed. One where more than a single video codec is used by an application, at times within the exact same session.
Here are a few suggestions for you to explore:
- Support higher complexity codecs on 1:1 calls only, dynamically switching to other video codecs if and when a call grows beyond two participants
- Dynamically switch to a higher complexity codec on low bitrates
- Enable decoding in as many codecs as possible in parallel on a device, and then deciding what the encoder should send based on its CPU capabilities
- Using multiple video codecs in simulcast – for example using AV1 with very low bitrate and next to it use VP8 or VP9 at higher bitrates. Simulcast doesn’t support this (yet), but you could open two separate peer connections with different codecs and bitrates to achieve a similar outcome
Is it worth it? Maybe. You tell me if enhancing video quality in your application is important. Venturing into the multi video codec realm in WebRTC is about the 80% effort that yields the last 20% improvements. Go there once you’ve finished pursuing all other simpler optimizations.
WebRTC trends in 2021Last month I hosted a workshop about WebRTC trends in 2021.
I covered optimizations of a single video call, voice suppression, background blurring, E2EE and video coding aspects. The challenge of which video codec to choose was there as well.
The sessions have been recorded and are now available as an online course on my website. If you are interested, you can register for it.
The post 🎲 Which video codec to use in your WebRTC application? 🎲 appeared first on BlogGeek.me.
WebRTC Trends for 2021 (and beyond)
2021 is set out to be the year of technical debt and quality optimizations. Check out these WebRTC trends to keep up to speed with communication technologies.
{kind=link}
Last year was a very interesting and weird year. The vibe of 2020 was dictated by the pandemic and the quarantines around the globe. For those in the communication space, this meant a huge acceleration in demand, scale and the scope of work you had in front of you.
Table of contents- WebRTC and expectations
- Google and WebRTC in 2021
- WebRTC Trends in 2021
- Trend #1 – Bigger WebRTC meeting sizes
- Trend #2 – De-noising: Background replacement and noise suppression in WebRTC
- Trend #3 – A focus on WebRTC user privacy
- Trend #4 – WebRTC Investments in VP9 and AV1
- An increase in use cases and markets
- Upcoming WebRTC Trends worksop
When I started last year, I talked about the expectations of WebRTC. I tried explaining the concept that WebRTC, more than anything else, is driven by Google and controlled by Google. It was a kind of a follow up to my article on the artificial intelligence roadmap of Google for its “WebRTC Pro” implementation.
Since then, Google introduced noise suppression, background blur and other AI trinkets in Google Meet. All AI features. All were delivered outside of WebRTC but tightly coupled with the WebRTC implementation in Chrome.
What changed since then is the focus. It is great talking about bots and drones. AR, MR and XR. 360 videos, 4K and 8K resolutions. But it gets us nowhere.
We came back to the basics and the basics have changed along with the pandemic.
As developers, we need to follow the trends. Be where our users need us and fill out their requirements. This is also true of WebRTC, and being owned by Google, it means we know where it is (roughly) headed.
Google and WebRTC in 2021{kind=link}
While Google uses WebRTC in multiple services, there are only 2 that matter for WebRTC trends in 2021: Google Meet and Stadia.
Google MeetIn the latest Gartner magic quadrant for meeting solutions (September 2020), here’s who you find:
Google doesn’t make it into a leaders position in meeting solutions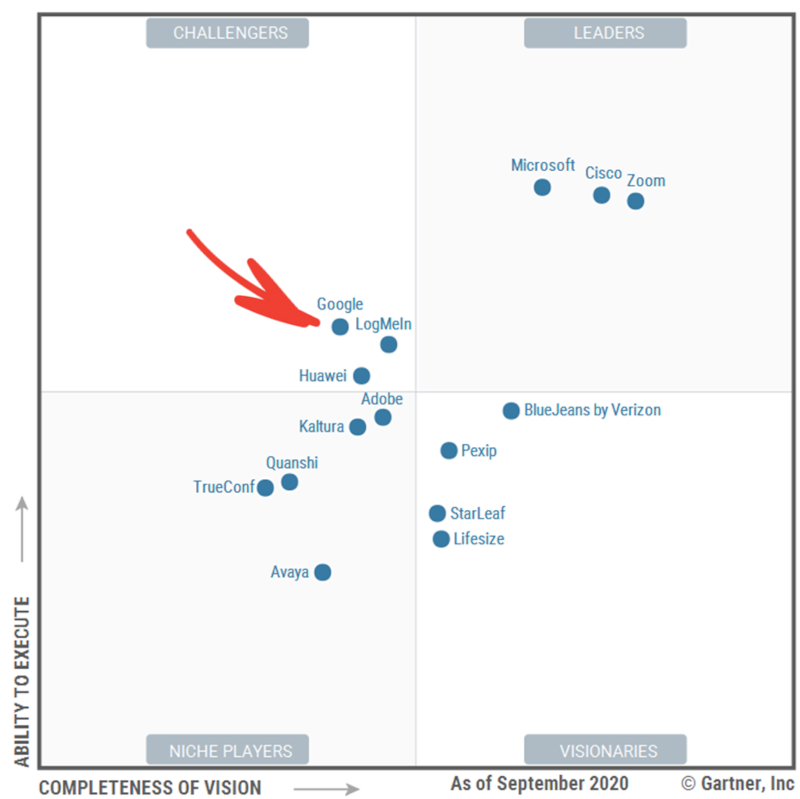{kind=link}
The leaders? Zoom, Cisco and Microsoft. Google is far behind.
2020 being the year of video meetings, and with Google investing in WebRTC and Meet, this has to hurt.
Google invested heavily in 2020 in and around WebRTC.
You could place their investments in two main areas:
- Optimizing the code – finally someone took the time to optimize the code and make it more performant and stable on multiple platforms and devices. This is an ongoing work that can still be seen today with each and every release. Google is starting to look at real time video processing as a profession and not a hobby
- Beefing up the feature set – to meet with what competitors are offering. This trickles back into WebRTC’s capabilities
That trickle-back is important. The 3 leaders in meetings?
- Zoom makes no use of WebRTC, which means it isn’t “limited” by WebRTC’s limitations (or advantages)
- Microsoft Teams offers a subpar experience on browsers. Just try to connect to a video call from Chrome and not the Teams app – you’d be surprised how poor and backward the service feels
- Cisco is improving with WebEx on the desktop. But a lot of the focus and features introduced are outside of the scope of WebRTC. Like the roll out of AV1 support in WebEx
{kind=link}
Stadia is Google’s cloud gaming platform.
It is still early days for both Stadia and cloud gaming, but a few interesting things have happened in this industry:
- The pandemic got more people to play games. Especially kids. My son plays it now in-between his virtual lessons as well as during the rest of the day. With shelter at home and distancing, this becomes a way to stay connected with friends
- Cyberpunk 2077 video should have been the incentive to join the platform. Gaming consoles like the PlayStation 4 and Xbox One couldn’t handle the game’s high end requirements. Using Stadia or other cloud gaming platform was a reasonable solution. Until bugs were reported about the game itself, causing it to tank globally. Not sure if and how that affects Stadia
- Epic Games battling it out with Apple on its App Store tax rules, with the only potential solution for gaming aggregators being a browser based approach instead of an installable mobile app
- Stadia, being cloud and browser based “enjoys” this
For now, Google seems committed to Stadia. Both Chrome and recently Safari added support to VP9 profile 2. This means a higher color depth than what is common for video conferencing, which is better suited for high end gamers.
Just like Meet, whatever Stadia will need from WebRTC will find its way into WebRTC.
WebRTC Trends in 2021The trends affecting WebRTC in 2021 are based on two main aspects then:
- What Google needs for Google Meet and Stadia
- What many developers are trying to develop with WebRTC
What comes from developers these days is the expansion of remote-everything. There are many domains that aren’t getting heard enough, simply because they are new to the scene. What I think is most interesting is that the mainstream video communications space is still the one setting the agenda for WebRTC.
The 4 biggest trends for WebRTC in 2021 are driven by video communications. Here they are:
Trend #1 – Bigger WebRTC meeting sizesOur first trend of 2021 for WebRTC? Meeting sizes. Something we’ve started focusing on only last year.
We used to want higher resolutions. At any given point in time, there was a company pushing the envelope in the resolution for video conferencing. Since we got to HD, that trend stopped. Vendors still tried marketing and selling 4K as a value proposition for video conferencing, but this hasn’t stuck. The high end of the market vanished, leaving us with a new number to focus on. The number of people in a “gallery view”.
{kind=link}
With Zoom doing 49, this seems to have become the magic number everyone is aiming towards.
WebRTC was great for smaller meeting sizes, but going beyond 16 video streams in a single session was always challenging. I like using this slide to explain it:
The bigger the meeting size in WebRTC, the higher the complexity of the solution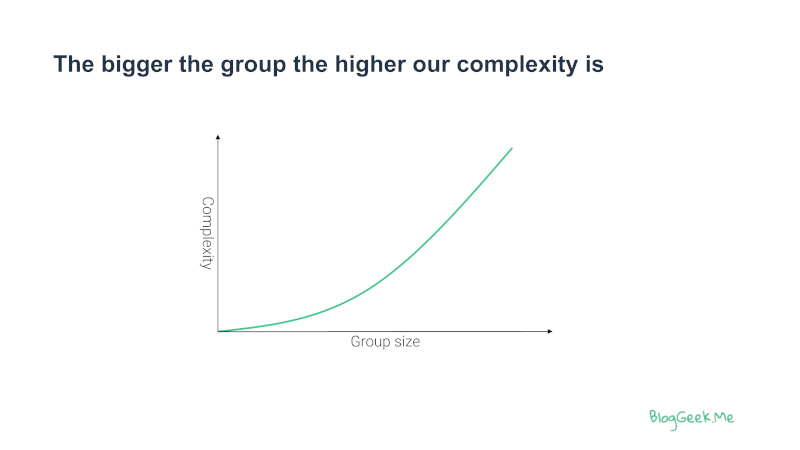{kind=link}
The growing complexity comes with the need to employ ever greater techniques and tricks for optimization. Scaling from 2 users to 10 requires a different approach than scaling towards 50 or 100 users. Aiming for 1,000 users in a meeting needs a slightly different architecture. Going for 20,000 or more necessitates again other tools.
There are now two distinct areas that require large scale WebRTC meeting sizes:
“Traditional” meetings – we had large meetings of 20 or more people, but the people simply convened in 3-4 meeting rooms and connected these meeting rooms. Now each person is a device in the meeting.
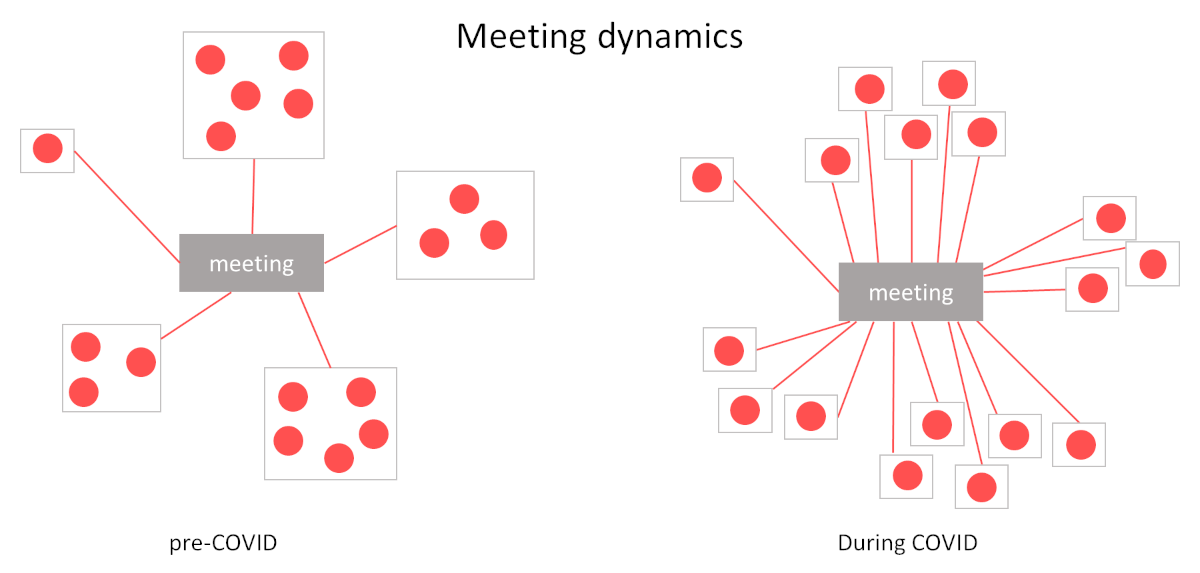{kind=link}
Large conferences – we are now trying to copy the real world activity of industry conferences along with entertainment activities (comedians, talk shows, magicians, sporting events, …) and turn them into virtual events. Large online conferences.
These two are different in nature and in the techniques and technical solutions for them.
Google is focused on the “traditional” meetings with their work on Google Meet, which means the optimizations done inside WebRTC’s code as well as enabled on top of it are built to fit this class of problems. The large conferences have a bigger challenge to deal with and less “direct” support from Google and WebRTC.
Trend #2 – De-noising: Background replacement and noise suppression in WebRTCThe second WebRTC trend for 2021 is a bit more surprising. I don’t think we would have cared about it much without the pandemic.
{kind=link}
Need better media quality? Buy a better camera.
That’s what I did at the beginning of the quarantine. I had to quadruple the number of machines at home with quality peripherals. Instead of only me in meetings we’re now 4 people in meetings, each needing his own different environment. That was obvious to me. Still challenging to do but obvious. We’re also lucky to be able to cater for the four of us in our apartment having a place for each to handle his needs without too much noise seeping out to the others.
Homes with more people? Smaller apartments? How would they handle it?
When we were all in offices things were simpler. The office space was designed (or then redesigned) to meet the needs of video calling. An IT person took care of the space. Someone purchased and installed equipment that fits the needs.
As we’ve all entered a pandemic with quarantine all that careful planning and preparation was thrown out the window. People had to use whatever they had and make do with it. And what did we find out? That there’s background noise and a user’s privacy we need to deal with.
That child from 2017 who barged into his father’s interview and was live on TV? That’s all of us now. It has become an accepted norm. People working from home. They have a personal life with family and kids, and kids are part of the scenery.
Same for the laundry or other artifacts that now reside behind a person speaking in a video call. How do you make all that go away? How do you reduce the noise of the neighbors running on top of your head while you write these words on a keyboard (literally)?
A rather old/new requirement is to be able to get rid of all of that. Background blurring and replacement. Noise suppression and noise cancellation. All things that were nice to have are becoming common requirements in meeting solutions.
They aren’t part of what comes with WebRTC, but somehow, you need to make them happen with WebRTC.
Trend #3 – A focus on WebRTC user privacy{kind=link}
Zoom and security issues anyone?
I am not here to gloat. Zoom did a bad job at security and privacy before 2020. It did a great job of fixing these issues in record time during 2020.
The issues around Zoom were both about security and privacy. Privacy of the users from other users and hackers, but also from Zoom itself.
This focus on user privacy found its way to WebRTC as well and for the same reason. Zoom is now how every communication company measures itself by, for better or worse.
There are many things to deal with when it comes to WebRTC security and the latest advancement there is E2EE enablement in media servers. The ability to offer end-to-end encryption in a group video call. It is now possible due to the introduction of Insertable Streams to WebRTC.
How is that used? What would it require of you to implement? How would that affect other requirements and features in your service? We are going to find that out during 2021 as more vendors will roll out E2EE solutions with WebRTC.
Trend #4 – WebRTC Investments in VP9 and AV1Video codec technologies come in stages. The industry at large has started adopting HEVC, with Apple leading the charge. VP9 has been slow to catch up. And we’re already in the next round of codecs with AV1 being hammered as the next big thing and something called VVC breathing down its neck.
WebRTC has been predominantly a VP8 phenomena, with a trickle of H.264. Here’s my estimate on video codecs use in WebRTC:
Hint: look at area differences and not height in this graph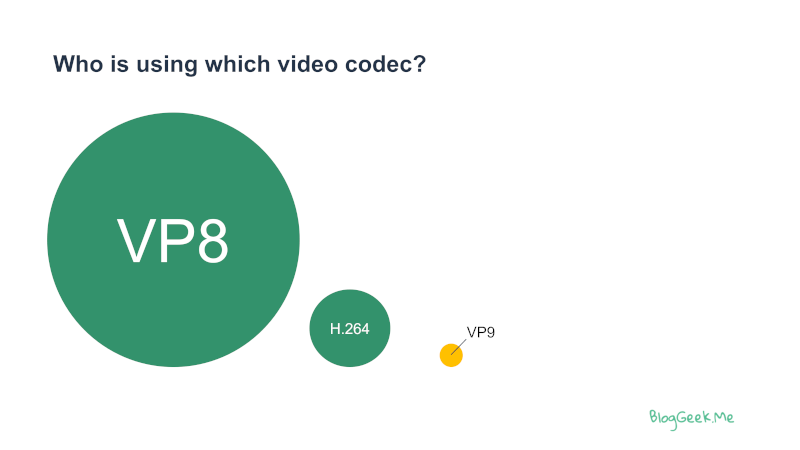{kind=link}
What is happening now is companies who are looking at VP9 and AV1 trying to make use of them for different use cases and scenarios.
Cisco just announced using AV1 in screen sharing for WebEx in native PC application when that is made possible.
We will see more of that in 2021. Companies experimenting, using and launching products that use more VP9 and even AV1.
An increase in use cases and marketsWebRTC is breaking out to additional markets. Large events, live streaming and even cloud video editing.
All these necessitate new features and capabilities to be added to WebRTC itself.
Now that WebRTC 1.0 is finally being finalized there is going to be a growing focus by the W3C on what comes next. If you have requirements that require a change in WebRTC, it might make sense for you to join the W3C and make your voice heard in affecting where WebRTC is headed next. Ping me if you’d like to discuss this.
Upcoming WebRTC Trends worksopNext month I’ll be conducting a workshop that covers these topics. The trends and what to do with them. It will offer actionable advice on what you should do in 2021 and it will be interactive in nature.
My last workshop about differentiation in WebRTC was well attended. Here is what Andrey Abramov of Doxy.me had to say about it:
Thank you very much for the 3 weeks workshop on which you dove us into the WebRTC. It was really interesting and useful. I have learned a lot and look like now I have a better vision of what to do to improve UX of our calls on Doxy.me. Thanks for the records as well! I will be reviewing them from time to time to recall.
It was great! Thank you!
This new workshop, WebRTC trends for 2021, will take place during February, in 3 consecutive sessions of 2 hours each.
Space is limited, so if you are interested, register sooner rather than later.
See you at the workshop.
Register to WebRTC trends for 2021 workshopThe post WebRTC Trends for 2021 (and beyond) appeared first on BlogGeek.me.
A blueprint to improving WebRTC media quality using AI
Before jumping on the ML/AI bandwagon of WebRTC media quality, make sure you’ve exhausted all of your other optimization alternatives.
TL;DR – make sure you optimize for media quality without AI before jumping to using AI…
In 2018 and 2019 at Kranky Geek we’ve started looking at machine learning. We’ve handpicked speakers and sessions who deal with these topics. We’ve done so for both voice and video technologies. The intent and idea behind this was to fit to the times. Everyone’s been doing AI so why not us in the context and domain of WebRTC and communication technologies?
It made perfect sense.
Then came 2020 and… changed everything. No one was really interested in AI or how to improve quality of experience with it. It was now used mainly for bots with the purpose of handling large loads of calls (call deflection and agent assist type technologies).
At times, it seemed like we were all back to basics. We now had to start scratching our heads and see what can be done to improve quality.
Time for some quick winsAt Google and elsewhere, I am sure that a manager somewhere higher up came, saw the work that is being done, received an explanation how research into this machine learning stuff was progressing and showing promise, but in many ways required, well, more research, before it could be seen as anything that is close to being production ready.
And as managers do in these situations, they smack the table and say something like “I want quick wins”. So the developers went back to the basics. Trying to figure out what quick wins they can find to squeeze a bit more quality of that thing they had called WebRTC.
Quite surprisingly – it worked!
There seems to be ample room for optimizations. If you ask me? Someone forgot to try and squeeze this lemon properly.
There’s more room for optimizations of WebRTC before we resort to machine learning Google’s optimizations of WebRTC’s codeIt started somewhere with the pandemic.
One of the first indications was this tweet by Serge Lachapelle (former product manager for WebRTC at Google and leading Google Meet at the time of tweeting).
@googlechrome 83 is now in beta with interesting changes to the video compositor. It should free up some CPU cycles when using @webrtc apps such as @whereby @confrere_video and #GoogleMeet
— Serge Lachapelle (@slac) April 17, 2020Apparently, the video compositor wasn’t making the most out of the hardware it was using…
Since then we’ve seen some additional optimizations, though most of them taking place in the application level on top of the WebRTC implementation itself.
At Kranky Geek, Google discussed at length the optimization work it is working on. Mostly, making sure that video processing doesn’t take up too much CPU.
Too many media format conversions in the WebRTC media pipelineApparently, Chrome is doing way too many video format conversions between getting the frames from the camera until it encodes and sends it out. Each conversion eats up CPU and I/O, generally killing the whole internal bus of the machine. Oh – and it means memory copies. Lots and lots of memory copies.
Video processing 101: zero copy is what you’re striving for.
We’re 10 years into WebRTC and the leading team behind WebRTC is just now starting to look at zero copying.
There are other areas and aspects where optimizations are taking place. Once the Kranky Geek videos will be ready and published, I’ll add the relevant one here.
Still got optimization juice in this lemon. Expect better performing WebRTC in the coming Chrome releases.
Rushing towards 49-gallery view and 50+ group sizesAs the pandemic hit, Zoom grew. The media was filled with their gallery view.
Zoom’s 49-gallery view. The holy grail of video group calls?One use case that didn’t exist before the pandemic is large video calls. Up until today, we used to take these video meetings in the office inside meeting rooms. Cramming a few people in each room in a remote office and doing a call with 2-4 such rooms. Maybe someone joined from home or a hotel. You could see meetings with 10 participants. Sometimes. But the need just wasn’t really there.
The pandemic hit. People are now at home. And communicate with video remotely. A meeting of 4 became a meeting of 20 just because the participants are now sitting at home.
Even worse, schools are now remote. Each class has 20-40 students in it. And the teacher wants to see them all.
This made Zoom’s gallery view so popular (even if a tad useless if you ask me). It also made the magical number 49 magical. The holy grail of what is needed of a video conferencing service in a pandemic. Doesn’t matter if everyone is muting their video.
49.
Microsoft and Google announced plans for supporting it. Then started running towards that value, each rising in the number of tiles in his gallery, reaching 49 recently.
Facebook grew from a meeting of 8 to meetings of 50.
Meetings are larger and longer now.
And again, we found the ways to make it happen with WebRTC.
Best practices on group video scaling being rewrittenThere are a lot of mechanisms in WebRTC that enable an application to squeeze the lemon and gain back CPU cycles as it tries to optimize for larger group calls.
But we never did have a place where all these are found and explained. A body of knowledge and understanding of how to make it happen.
The larger the conference call size in WebRTC, the more complex the solution is going to be to implement itI’ve been in such conversations multiple times with multiple clients and developers. I’ve hosted a workshop on the topic and write an ebook on optimizing group video calls.
In my recent/upcoming update to the Advanced WebRTC Architecture course there’s a lesson dedicated to this specific topic. It isn’t as if the information isn’t there in the course – it is spread all over the course. But now there’s a lesson on this alone. Because it became interesting only in 2020.
We have traded the focus on what is important to us with video communications. A video conference’s scale trumps quality at the moment. While I do understand we all want both all the time, but there is still a tradeoff between these two qualities of a system.
The role of machine learning and AI in communicationsWhere does one fit machine learning and AI in this brave new world of large video conference calls?
Machine learning requires memory and CPU. Things we don’t have to spare at the moment in these large group calls. So we can’t just slap machine learning inference algorithms on the edge inside the web browser easily.
Edge inference in web browsers using WebAssembly is also brand new. So there’s no guide book to work with.
We won’t be using it to improve video quality or audio quality in the edge – we can’t really. Not enough CPU to spare.
There’s no real place for it on the server side either – that one requires decoding and encoding which are going to be CPU intensive and increase the costs of delivering the service. Pexip is doing that for auto zoom, but that’s because they are built as an MCU. Google decided to do this for noise suppression.
There’s packet loss concealment using machine learning now. And you can do super resolution for video to get better video quality. But in the end, all these are going to make a difference once CPUs have their own dedicated, standardized AI accelerators, like the new Apple M1 chip in them brand new Intel-less MacBooks. We just don’t have cycles to spare.
Which is why media quality has gone back to its roots. Here’s something I have in that workshop of mine:
First take care of your infrastructure as much as you can to improve media quality in WebRTCMachine learning should be added once we’re done squeezing that lemon for more performance and quality.
Google is now doing its part of optimizing the WebRTC codebase itself. It is your role to do it in your own infrastructure and application. Once done, the time will come to introduce some machine learning chops into it.
Until then? We need machine learning for two main tasks, and we see it already:
- Background blur and background replacements. We’re all humans but somehow we don’t want our kids to be in the way of our conversations
- Noise suppression. As we’re stuck at home, we can’t really control that crying kid of ours on the other side of the room
Does that mean you don’t need to invest in machine learning?
Hell no. you definitely MUST invest in machine learning.
Not for what you’ll be doing in 2021, but for what you’ll be launching in your product in early 2022. Which brings me to the heart of it all.
Machine learning is new and challenging. We’re still writing the playbook of what it means to use it for real time communications, inside a browser, using technologies such as WebAssembly.
You’ll need to decide on which use cases to invest, and what value you are going to derive of it. And you’ll need to plan for the long game here and be patient until you get results.
There’s a need to let the teams driving machine learning do the research and experimentation needed. But at the same time, they need guidance in where to look at and what to experiment with.
The post A blueprint to improving WebRTC media quality using AI appeared first on BlogGeek.me.
WebRTC Growth – is it a back-to-school pandemic phenomena?
WebRTC growth during 2020 came in waves, just like the pandemic and its quarantines. Here how it looks and where we are all headed.
Let’s look at some interesting performance indicators of WebRTC use and adoption.
2020 is the year of video communications.
2020 is also the year of WebRTC.
Table of contents- Unified Communications & WebRTC
- Gartner’s Magic Quadrant for Meeting Solutions (& WebRTC)
- A surge in use of WebRTC
- Where do we go from here?
In my introductory slides of my WebRTC workshop 4 months ago, I had that as a very strong theme:
The slide above illustrates what the statistics at the time were for the big meetings vendors.
Since then, the numbers have grown. Microsoft Teams, for example, reached 115M DAU. That’s Daily Active Users.
While not all of the growth is in video calls, these services have a video focus to them.
Out of these 4 vendors:
- Zoom doesn’t make use of WebRTC, and like it that way
- Google Meet is “all in” with WebRTC
- Microsoft Teams has WebRTC support to it, though with pretty limited capabilities
- Cisco WebEx supports WebRTC rather nicely
Guest access growth for Microsoft Teams and Cisco WebEx can be attributed to some extent to WebRTC. With Google Meet, it is all WebRTC related.
Gartner’s Magic Quadrant for Meeting Solutions (& WebRTC)Gartner has its nice magic quadrant diagrams. Here’s the one just published for meeting solutions:
Which of the vendors in this magic quadrant diagram use WebRTC? I’ve marked the vendors in red for you:
The ones not marked might have WebRTC – I am just not aware of it. The ones marked have WebRTC support in production in their products. How central is it to their product is a different question though.
The thing here is that no matter what magic quadrant from Gartner you’ll be looking at for whatever market category that involves communications, WebRTC will be used as the underlying technology by many of the vendors.
Contemplating if WebRTC is the technology to use? Look at the reds above.
A surge in use of WebRTCI decided to leave the best for last.
Chrome collects and shares statistics of JS API calls in the browser and their “popularity”.
Lets look how getUserMedia() looks like:
Source: here
Interestingly, we see an adoption curve where each round of quarantine raises the use of WebRTC to a higher level.
From a steady, boring 0.05% of use pre-pandemic, the new normal is settling well above 0.2% of the page loads.
How can we explain the rise from July to October? Is this a sustained growth happening as the pandemic found its second wave in different countries and social distancing gradually came back in force throughout the globe? Is it due to the fact that schools started opening around the world in August and September, many of them strictly remotely? Is it due to more services being introduced online that offer WebRTC based communications in them?
AddTransceiver, AddTrack and AddStream show similar trends for the most part.
If you ask WebRTC, we’ve reached the peak of the second wave of the pandemic.
Where do we go from here?Two alternatives:
- A third pandemic wave. Will that raise usage even further?
- Vaccine. Even a promise of one sent collaboration stocks down
On a more serious note though, the huge surge in WebRTC traffic brought with it new use cases and a lot of learnings regarding scaling and operationalizing WebRTC.
In our Kranky Geek event next week, we will be discussing these topics a lot. Make sure you register to join us!
The post WebRTC Growth – is it a back-to-school pandemic phenomena? appeared first on BlogGeek.me.
What is WebRTC P2P mesh and why it can’t scale?
If you are planning to use WebRTC P2P mesh to power your service, don’t expect it to scale to large sessions. Here’s why.
Every once in a while someone comes in with the idea to broadcast or conduct a large scale video session with WebRTC without the use of media servers. Just using pure WebRTC P2P mesh technology.
While interesting as a research topic for university, I don’t think that taking that route to production is a viable approach. Yet.
Table of contents- What is WebRTC P2P mesh?
- Bandwidth challenges in WebRTC P2P mesh
- CPU challenges in P2P mesh
- Alternatives to WebRTC P2P mesh
- A word about WebRTC data channel mesh
If you are focusing on data only WebRTC mesh, then skip to the last section of this article.
When dealing with WebRTC and indicating P2P or mesh, the focus is almost always on media transport. The signaling still flows through servers (single or distributed). For a simple 1:1 voice or video call, WebRTC P2P is an obvious choice.
From a WebRTC client perspective, a 1:1 session is similar if it is done using P2P mesh or using a media serverThe diagram below shows that from the perspective of the WebRTC client, there is no difference between going through a media server or going P2P – in both cases, it sends out a single media channel and receives a single media channel. In both cases, we’d expect the bitrates to be similar as well.
Making this into a group call in P2P translates into a mesh network, where every WebRTC client has a peer connection opened to all other clients directly.
WebRTC mesh architecture. Or is it mess architecture? Why use WebRTC P2P mesh?There are two main alluring reasons for vendors to want to use WebRTC P2P mesh as an architectural solution:
- It is cheaper to operate. Since there are no media servers, the media flows directly between the users. With WebRTC, oftentimes, the biggest cost is bandwidth. By not routing media through servers as much as possible (TURN relay will still be needed some of the time), the cost of running the service reduces drastically
- It is more private. Yap. As the service provider you don’t have any access to the media, since it doesn’t flow through your servers, so you can market your service as one that offers a higher degree of privacy for the end users
If WebRTC P2P mesh is so great, with cheaper operating costs and better privacy, then why not use it?
Because it brings with it a lot of challenges and headaches when it comes to bandwidth and CPU requirements. So much so that it fails miserably in many cases.
It is also important to note here that in ALL cases of 3 users or more in a call, alternative solutions that rely on media servers give better performance and user experience. Always – at least as long as the media servers infrastructure is properly deployed and configured.
Bandwidth challenges in WebRTC P2P meshAssume we want pristine quality. Single speaker, 10 listeners.
The above layout illustrates what most users of this conference would like to see and experience. The speaker may alternate during the meeting, switching the person being displayed in the bigger frame.
As we’re all watching this on large screens (you do have a 28” 4K display – right?), we’d rather receive this at HD resolution and not QVGA. For that, we’d want at least 1.5Mbps of the speaker to be received by everyone.
Strain on the uplinkIn a mesh topology, the speaker needs to send the media to all the participants. Here’s what that means exactly:
In WebRTC mesh, we put a bigger strain on the uplink1.5Mbps times 10 equals 15Mbps on the uplink. Not something that most people have. Not something that I think my strained FTTH network will be able to give me whenever I need it. Especially not during the pandemic.
In an office setting, where people need to use the network in parallel, giving every user in a remote meeting 15Mbps uplink won’t be possible.
On top of that, we’ve got 10 separate peer connections to 10 different locations. WebRTC has its one internal bandwidth estimation algorithm that Google implemented in libwebrtc, which is great. But how well does it handle so many peer connections on the client’s side? Has anyone at Google ever tried to target or even optimize for this scenario? Remember – none of Google’s own services run in a mesh topology. Winning this one is going to be an uphill battle.
Bandwidth estimation on the downlinkLet’s look at the viewers/subscribers/participants/users or whatever else you want to call them.
If we pick a gallery view layout, then we are going to receive 10 incoming video streams. Reduce that to 9 for layout simplicity and we get this illustration:
There are 9 other users out there who generate video streams and send them our way. These 9 streams are competing on our downlink network resources and for our machine’s attention and CPU.
Each of them is independent of the others and have little knowledge about the others.
How can the viewer understand his downlink network conditions properly? Let alone try to instruct these sends on how and what to send. A media server has the same set of problems to deal with, but it does that with two main advantages:
- It controls all the videos that are sent to the viewer, and it can act uniformly as opposed to multiple browsers competing against each other (you can try to sync them, though good luck with that)
- You can put all incoming streams in a single peer connection from the server, which is what Google Meet does (and probably what Google is focused on optimizing for in their WebRTC implementation)
Then there’s the CPU to deal with in WebRTC P2P mesh.
Each video stream from our speaker to the viewers has its own dedicated video encoder. With our 10 viewers, that means 10 video encoders.
A few minor insights here if I may:
- If you aim for H.264 hardware encoding, then bear in mind that many laptops allow up to 3-4 encoded streams in parallel. All the rest will be black screens with the current WebRTC implementation
- Video coding is a CPU (and memory) hog. Encoding is a lot worse than decoding when it comes to CPU resources. Having 10 decoders is hard enough. 10 encoders is brutal
- 10 or more participants in a video call is hard to manage with an SFU without adding optimizations to alleviate the pains of clients and not burn their CPU. And that’s when each user has a single encoder (or simulcast) to deal with
- Your Apple MacBook Pro 2019 with 16 cores isn’t the typical device your users will have. If that’s what you’re testing your WebRTC mesh group video calling on then you’re doin’ it wrong
- I am sure you thought that using VP9 (or AV1 or HEVC, which aren’t really available in WebRTC at the moment) will save you on bandwidth and improve quality. But it eats even more CPU than VP8 or H.264 so not feasible at all
So. going for a group video call?
Want to use WebRTC P2P mesh?
You’re stuck at 300kbps or less for your outgoing video even if your network has great uplink. Because your device’s CPU is going to burn cycles on encoding multiple times.
Which also means that people aren’t going to like hearing their laptop’s fans or touch their heating smartphone (and depleting battery) on that call.
Can we do better?Probably. A single encoder would make the CPU problem a wee bit smaller. It will bring with it headaches of matching the bitrate to all viewers (each has his own network and device limitations).
Using simulcast in some manner here may help, but that’s not how it is intended to be used or how it has been implemented either.
So this approach requires someone to make the modifications to the WebRTC codebase. And for Google to adopt them. Did I already say Google has no incentive in investing in this?
Alternatives to WebRTC P2P meshYou can get a group video call to work in WebRTC P2P mesh architecture. It will mean very low bitrate and reduced video quality. But it will work. At least to some extent.
There are other models which perform better, but require media servers.
WebRTC offers media server alternatives to mesh in the form of SFU and MCUUsing an MCU model, you mix all the video and audio streams in the MCU, making sure each participant receives and sends only a single stream towards the MCU.
With the SFU model, you route media around between participants while trying to balance their limitations with the media inputs the SFU receives.
You can learn more about in my WebRTC multiparty architectures article.
A word about WebRTC data channel meshI haven’t really touched WebRTC mesh architectures for data channels.
All the reasons and challenges detailed above don’t apply there directly. CPU and bandwidth relied on the concept of needing to encode, send, receive and decode live video. In most cases, this isn’t what we’re dealing with when trying to build mesh data channel networks. There, the main concern/challenge is going to be proper creation and connection of the peer connections in WebRTC.
If what you are doing isn’t a group video call (or live video broadcast from a browser to others) then a WebRTC P2P mesh architecture might work for you. If it will or won’t is something to analyze case by case.
The post What is WebRTC P2P mesh and why it can’t scale? appeared first on BlogGeek.me.
CPaaS in 2020 and my WebRTC API report
In the last 2 months I’ve dived into the world of CPaaS again, updating my WebRTC API focused report. Oh, and there’s a new free ebook.
There have been many changes since my last update,so this one was greatly overdue.
API platforms changed hands due to mergers and acquisitions. Vendors joining the market. Others leaving or just pivoting away from APIs.
And then we had AWS and Azure entering the CPaaS market.
What I did in these last two months was interview and review all the vendors in my report again, to see what has changed and update that part of the report. I learned a lot from the process.
As with every time where I shift focus to a certain market, I took the time to process my own thoughts by writing them down here in a series of articles.
Here are two things I wanted to share with you, as well as announce my next upcoming projects.
Table of contents- Choosing a WebRTC API report – 2020 version
- CPaaS in 2020 – a free ebook
- Advanced WebRTC Architecture Course – update & office hours
- WebRTC Insights – a new service
I finished and published the WebRTC API report last week. The result:
- 254 pages
- 24 vendors
Agora decided to sponsor this report (thanks a bunch!). They are one of the interesting vendors in this space, offering an IP video/voice focused platform with their own data centers spread across the globe and a lot of research done in machine learning to improve media processing.
If you are looking to learn more, then you can:
- Read the WebRTC API report overview
- Get the 4-pager of Agora from the report (each vendor covered in this report has a 4-pager)
- Purchase the report online
The previous 3 articles in my site here were all focused on CPaaS, looking at different angles on how CPaaS is changing.
The first one dealt with the future of CPaaS, especially considering the pandemic and how it affects everything and everyone.
In the second article, I looked at AWS Chime SDK and Azure Communication Services, trying to understand what their entry into CPaaS is going to change in the market.
For the third and last article, the focus went to Twilio Signal 2020. Considering how they redefined the market in the last 4 years in each such event, this event was a bit of a downer. It did bring with it many insights.
If you’re more into printing and reading, or sharing with others, then I packaged all of these 3 articles into one ebook, making it easier to consume.
I called the ebook CPaaS in 2020 – a market in transition. Because this is what it is…
Download my CPaaS in 2020 ebook Advanced WebRTC Architecture Course – update & office hoursWith my WebRTC API report now updated and finally launched, I can go back to focusing on other projects I am running.
My WebRTC Courses have been around for over 4 years now. I’ve been updating them regularly and I am doing it again to my main signature course – the Advanced WebRTC Architecture training.
UpdatesThere are going to be 2 new lessons and around 10 lessons that are already being updated and recorded all over again.
The purpose is still to make this the best alternative out there to learning WebRTC.
Office hoursAlongside the updates, I will be starting another round of office hours for the course. These will start in December.
The office hours is where students can come and learn online and in-person with me specific topics in WebRTC, as well as ask questions about anything related to WebRTC – and their own projects.
If you were thinking of learning WebRTC, then the best timing for it would be to enroll now and join the office hours. These are complementary to the course and open for anyone with a valid course subscription.
WebRTC Insights – a new serviceFollowing and catching up with everything in WebRTC is time consuming. It is also tedious. And you need to know where to look and what each bit of information means to you.
To make this a wee bit easier, I’ve decided with the help of Philipp Hancke to start a new service together – WebRTC Insights
In this service, you receive an email every two weeks. This email includes all the important changes to WebRTC
- Bug tracking of browser related WebRTC issues we feel are important
- Select libwebrtc code commits that we found interesting
- discuss-webrtc forum messages
- Critical PSA announcements from browser vendors
- W3C/IETF mailing list items
- Market news related to WebRTC
- Things we hear from other vendors that we can share
This gives you actionable insights to your own planning and reduces the risks in your development. Both Philipp and me have been doing this for a while, but doing it together brings it to a new level.
If you want to learn more and subscribe to this service, then check the new WebRTC Insights page.
The post CPaaS in 2020 and my WebRTC API report appeared first on BlogGeek.me.
Twilio Signal 2020. I expected more from the leading CPaaS vendor
Twilio Signal 2020 occurred virtually this year. The number of new announcements or market changing ones was low compared to previous years. I expected more from Twilio as the leading CPaaS vendor.
Table of contents- Twilio Signal – past events
- Twilio By the Numbers
- Nike and digital transformation
- Twilio Microvisor
- Twilio Video WebRTC Go
- Twilio Flex ecosystem
- Twilio Frontline
- Other announcements
- Machine Learning was missing
- The coming CPaaS fight is in the enterprise
Twilio Signal is Twilio’s yearly event where its major announcements are made. It is also a gathering place where customers, partners and even Twilio CPaaS competitors come to meet. This year, as all other events, Signal was virtual. Twilio built its own hosting platform and event experience and did a good job at that.
Twilio Signal – past eventsI’ve watched the keynote twice, and several of the other sessions, including all major announcement sessions. I came out of this feeling a wee bit disappointed. There was nothing really interesting or groundbreaking this year. Especially not if you compare it to some of the previous years:
- 2015 – Copilot, Video, IP Messaging, …
- 2017 – Engagement cloud; shifting from low level building blogs to higher abstractions. Especially with Twilio Studio
- 2018 – this year was about Flex, and moving into contact centers directly
- 2019 – Twilio Conversations, Media Streams, SendGrid (email), Twilio CLI, …
In 2020, we’ve seen Twilio Microservices (the Electric Imp acquisition), Frontline, Video Go, Event Streams and Verify Push.
Twilio By the NumbersThe main keynote by Jeff Lawson, Twilio CEO, had 3 components to it, with 3 main messages:
- Twilio is big
- Social good
- New product announcements
I’ll focus on the big and new parts here.
Twilio is now 12 years old and it has accomplished a lot. Jeff threw the “Twilio is big” numbers too fast for my taste, not even letting some of the big numbers register in our minds properly.
Here are the numbers. I tried aligning them with last year’s numbers from Twilio 2019:
20192020Interactions750B1TUnique phone numbers2.8B3BCalls/minute32,500–Peak SMS/second13,000–Email addresses3B/quarter50%Video minutes–3BCustomers160,000200,000+Developers6M– What the numbers mean- I still don’t understand what interactions mean, but the number is growing ridiculously fast, so it must be a good thing (I’d love to know how it is calculated)
- Voice and SMS is out (no calls/minute or SMS/second numbers this year)
- Unique phone numbers indicates reachability and 3 billion is a nice number, showing decent growth from last year
- Email moved from a number to a percentage, making it even less accurate or interesting. How would one know what an email address represents? There are so many of them that are spammy or just an alias to other addresses.
- For the first time video is important to Twilio. 3 billion is a large number, but not overly so (more about this later)
- The number of customers has grown significantly
- The developers number was useless to begin with and is finally not shared at all
Jeff alluded to the new normal, forced on us due to the pandemic. In many ways, this has been the main theme of Signal and the sessions.
My gripe with the “new normal” moniker to our situation is that there isn’t anything normal about it and it isn’t really here to stay.
Yes. We are seeing an accelerated move towards digital transformation and the cloud, but some of this shift, and especially the high usage in some sectors (such as education) aren’t here to stay post-pandemic.
For me, there’s no “new normal”. Just a transition to one, which will take time. How the future is going to look is hard to say from our current position.
Which leads me to the interview Jeff did with John Donahoe, Nike CEO.
Nike and digital transformationJeff picked John Donahoe as the first person to interview during the keynote. It is an interesting choice.
I found it a tad ironic to get an explanation about social good and how Nike in all its years promoted social causes. It got me thinking about the Nike sweatshops. Other than this little history reframing that was done, the interview was quite good.
Two sentences that John said really resonated with me:
“Every business in the world is embracing digital transformation. We all have no choice”
The shift towards making businesses more digital has been inevitable.
Just think of all the on premise contact centers and what they now have to do when all of their agents are working from home. Or how all brick and mortar stores need a digital footprint to be able to even stay in business and sell throughout the quarantines.
“There is no finish line”
I should start using it myself.
There are a lot of discussions around build vs buy that I participate in, especially when it comes to the decision to build a WebRTC infrastructure versus buying an existing one via CPaaS vendors. In many cases, the argument and focus is on the initial development effort and a lot less on maintenance. The thing about maintenance is that it is almost as hard as the initial development, especially because there is no finish line – the product team will always ask for more features and capabilities which will drive more investment.
Twilio MicrovisorThe first announcement made during the keynote was about a new product – Twilio Microvisor.
The Twilio Microvisor is an extension of the Twilio Super SIM and its Internet of Things initiative, which many don’t even couple and view as CPaaS (I’ve been ignoring it as well).
The world of IOT and M2M is a challenging one. It includes different networks and carriers, differences in geographies and regulation, different hardware devices and chipsets.
Earlier in the year, Twilio acquired Electric Imp. This acquisition is now the Twilio Microvisor.
Up until now, the only real touching point that Twilio had with the physical world was their Super SIM. With Microvisor (and Electric Imp) that changes, and Twilio is mucking around with microcontrollers, firmware and hardware.
It the special announcements session, Evan Cummack, GM of IoT at Twilio, explained that there was a gap in the market – as a developer you either had to begin from scratch or use readymade solutions:
The gap between IOT alternatives of developers: DIY or bespoke solutionsHe ignored a few of the competitors for the Twilio offering, but these are less flexible and open anyways.
What Twilio is doing with Microvisor, is taking care of a few important aspects of IOT development:
Twilio Microvisor features takes care of the heavy lifting of security for developers- Secure Boot
- Secure FOTA (Firmware Over The Air)
- Secure Debug
- Secure Communications
The secure part here is key, as it is the one thing we struggle with greatly in IOT these days. This solution will remove a lot of the headaches of IOT development and get more products released.
It is also where Twilio is competing not with other CPaaS vendors but rather with cloud vendors, who also started offering IOT tooling in recent years.
Twilio Video WebRTC GoComing from the Video and WebRTC space, this is where I am most frustrated.
The need and growth of videoWith the pandemic going on, Twilio had to do something about video, an area where little investment on their part has taken place. Until 2020, this has been understandable. Growth came from elsewhere and it didn’t seem like video is that important.
All this has changed. Zoom exploded, Agora.io had a great IPO, and Twilio itself saw an increase of 500% of daily usage for its video.
Twilio reiterating the need and uses of video communicationThe one to talk about Twilio Programmable Video was Michelle Grover, Chief Information Officer. Her part of the keynote revolved around the market need. The main market verticals here were retail and health.
It was more a reminder that Twilio is doing video than anything else.
The new WebRTC announcementThe new announcement? Twilio Video WebRTC Go
What is Twilio Video WebRTC Go?
- A free, hosted WebRTC service
- Peer-to-peer, 1:1 sessions only
- Limited to 25 GB/month of TURN for media relay
For context, pricing of 25 GB/month on Twilio’s TURN servers in the US is $10/month.
If you developed your own signaling and your own application, relying on Twilio’s TURN servers, then switching to Twilio Video WebRTC Go will save you $10.
But what you really get here is Twilio Video P2P that costs $0.0015/minute. In this configuration, you get the full infrastructure and support of Twilio’s signaling, logging and SDKs practically for free if your service is smaller than 25 GB/month of TURN media relay. How many video sessions can this accommodate? That’s something you’ll need to calculate.
For Twilio this is a win, as it gets more companies to adopt its Programmable Video at a very low price to Twilio (remember – video isn’t a serious money maker for Twilio yet, so helping these smaller users to grow their business and then have them start paying is just fine). With all the video API services out there, a free offering from a large vendor is a first. While limited, it is probably useful for many companies starting their way with 1:1 video calling.
On open source and TwilioThe fact that Twilio is calling their reference apps “Open Source Video Collaboration Apps” is a bit silly. These are references/samples running on top of the Twilio Programmable Video API and are not meant, designed or easily usable on top of any other vendor or on top of any other infrastructure.
Calling a piece of code, no matter how big, open source, while forcing its user to consume other paid services in order to use it is not exactly open source.
This isn’t to say that this open source reference app isn’t useful. It surely is most useful. It gives developers a better starting point for their application, and Twilio has taken the time at Signal to offer a session titled “Accelerating Development of Collaboration Apps with Twilio Video” dedicated exactly to this.
It is a trend I see of CPaaS vendors going towards higher level abstractions. Twilio is doing that with nocode (=Twilio Studio), programmable enterprise (=Twilio Flex), reference apps for video (this one) and now with Frontline (later in this article).
Nothing new under the sun hereFor me this says that Twilio hasn’t invested in video as much in the last year or two. If they had, they would have announced something more thrilling and interesting. Maybe larger meetings, above 50 participants? Broadcasting capabilities? Noise suppression? Something…
Twilio Flex ecosystemThe keynote and the session had a lot of Twilio Flex content in them. This is less about developers and more about contact centers.
A show of force for Twilio Flex, but sharing customer logosIn this event, Tony Lama, Vice President, Contact Center Sales at Twilio mentioned in brief the fact that many features were added to Flex, but didn’t really delve into them too much. The focus was on the fact that Flex has customers and now has a thriving ecosystem of partners as well.
Lots of new features, none interesting enough for the keynoteThe main target for this year were the on premise contact centers – this is where Twilio is setting its sights – in the transformation these contact centers are going through as they are heading to the cloud (forced to do so earlier rather than later due to the pandemic).
This is why Twilio decided to focus on the ecosystem, making it into a big announcement:
This targets exactly the on premise contact centers, where large deployments with many agents and a lot of custom integration code and features were added over the years. An ecosystem around Flex gives Twilio the reach it needs.
It is also why Twilio introduced its latest Flex partner – Deloitte Digital – who offer system integration in this target market.
Twilio Flex and its current set of announcements is less about CPaaS and developers and more about content center as a service (CCaaS).
Twilio FrontlineIn that vein, the announcement of Twilio Frontline was made.
Interestingly, this was introduced by Simon Khalaf, SVP and GM, Messaging at Twilio.
Twilio Frontline is a new complete, closed, mobile application and service which enables employees in a company to directly communicate with customers through messaging channels.
The main benefits touted about Frontline? SSO (Single Sign-on) and CRM integration
- Both of these features aren’t building blocks or APIs at Twilio, which begs the question why not
- There’s nothing about programmability, APIs or building blocks here. This isn’t something by developers for developers
This is far remote from the developer roots and target audience of Twilio, so it will be interesting to see how this plays out and redefines Twilio itself. My guess is that Frontline started as a skunk works project during the pandemic, one that turned into a new product that is now looking for a home at Twilio and within its bigger storyline.
I wonder though, was this built on top of Twilio Conversations, which was introduced at Signal 2019, or is it something implemented on top of Twilio Flex?
If this was implemented on top of Twilio Flex (which I believe it was), then why is the SVP and GM of Messaging at Twilio the one introducing it? And why wasn’t it designed, developed and even introduced as a programmable solution? Part of Flex. Maybe even an “open source application” on top of Flex.
Frontline is an interesting product. But what does it have to do with Twilio?
Other announcementsThere was little in the keynote of Twilio about APIs and CPaaS and more about the higher level abstractions and complete applications (Flex and Frontline). This shows a maturity level at Twilio, where most of the CPaaS domains are already well covered by their APIs.
Two additional announcements of new features/products were made, though not in the keynote itself.
Twilio Event StreamsThat trillion human interactions? These are probably just events in the Twilio system:
This is the slide shared in the session discussing the new feature/product of Twilio Event Streams. It isn’t a trillion but it is close enough.
What Twilio did was consolidate all of its events into a single hook, calling it Event Streams, offering a single integration point for collection of events. The first sink selected for these events is Amazon Kinesis, with more to probably be added later, based on customer demand.
Moving towards consolidated data management shows maturity and an increase in the customers that are using multiple Twilio products.
Twilio Verify PushAnother new product/feature is Twilio Verify Push. This enables a mobile application to be used as a trusted device/app to validate login on another device (as well as on the device itself). The end result is reduction in the SMS volume.
While nice, I am waiting here for Google and Apple to close this gap and offer their own verification mechanisms to all instead of having application developers rely on third party services.
As for Twilio, this makes for a sensible and useful addition to their Twilio Verify service.
Machine Learning was missingWhat was missing at Twilio Signal 2020 is AI and machine learning.
No really interesting improvements shared about Twilio Autopilot. No cool introduction of noise suppression or other media processing machine learning capability. Nothing.
There were a few mentions on how Autopilot is used by customers during the create bots in order to deflect calls and handle the volume (nice stories that we’ve heard would be the main use case for Autopilot already).
The only “real” thing around AI? At the end of the keynote, Jeff Lawson had his short “live” coding session.
Jeff, coding “live”. Still magicalThis time, he went for using OpenAI’s GPT-3, a per-trained natural language processing engine. He made it understand TwiML constructs (the XML format used by Twilio sometimes) so that users can write a sentence of what they want, and the service would generate the TwiML for them. A nice toy to play with. I wonder what people would do from here with it, as it opens up a lot of questions, thoughts and ideas.
Machine learning is one of the main pillars I see in post-pandemic CPaaS offerings. Twilio has the skill set inhouse to pull this off, but they need to focus there more than they are doing today. They should probably also partner or acquire in this space to keep in pace with where the industry is headed.
The coming CPaaS fight is in the enterpriseThe enterprise story of Twilio came at the beginning of the keynote. Jeff wanted to make sure everyone knew and understood that Twilio is ready for the enterprise and being used by the enterprise. The careful selection of guests throughout the keynote showed that as well – they were all established enterprises. No cool startup this time. No crazy garage developers. Just formidable businesses that existed for years.
Twilio is ready for the enterprise, with all the relevant certificates and proceduresI decided to leave this to the end since this is where Twilio is being challenged.
The challenge comes in the form of Amazon and Microsoft going towards CPaaS. Both of these vendors are:
- Bigger, with a wider breadth of products and services targeted at developers
- Attractive programs for startups, giving them free “cash” on their platforms
- Better access and relationships with enterprises
- Global coverage and partner programs that are richer in depth, breadth and reach
Amazon will probably introduce machine learning capabilities such as noise suppression as part of its CPaaS offering soon. They have it available in Amazon Chime, so placing it in the Chime SDK is the next logical step.
Microsoft runs their CPaaS on the same infrastructure that Teams is running on. Twilio touts 3B video minutes a year while Microsoft Teams has up to 5B meeting minutes a day. I am sure that it accumulates to a considerably larger number than 3B video minutes a year.
Both Amazon and Microsoft have ways to go in stabilizing their APIs and attracting developers and attention to it. They might not be highly interested in this CPaaS business as much as Twilio is, so would probably never reach the same level of maturity and breadth of features and flexibility of Twilio. But they will surely win market share. Market share that could have easily been Twilio’s.
What is also very interesting to note is that while Amazon and Microsoft made a point of not mentioning WebRTC in the front of their CPaaS platforms (both of which are video first and use WebRTC), Twilio decided to bring WebRTC to the front with their new offering of Twilio Video WebRTC Go. I wonder which works better for enterprise sales.
Anyway, with 75% of contact centers still on premise, the enterprise market as a whole is still only starting its path towards digital transformation and with the new phrase I just adopted of “there is no finish line”, there is definitely room for growth for Twilio and its many competitors.
Interesting times ahead of our industry.
The post Twilio Signal 2020. I expected more from the leading CPaaS vendor appeared first on BlogGeek.me.
Cloud giants joining the WebRTC API game. How is that changing the CPaaS landscape?
Amazon Chime SDK and Azure Communication Services mark the entrance of the cloud giants to the CPaaS space, and they are doing it from a WebRTC API angle.
Ever since Twilio became popular, a question was raised over and over again:
When will one of the large IaaS players (Amazon, Microsoft or Google) acquire them or start competing with them directly?
There was no good answer. At least not until 2020, where 3 things happened:
- The pandemic hit us and we had to stay at home and shelter, or whatever
- Video exploded
- Amazon Web Services and Microsoft Azure both launched their CPaaS offering
This. Changes. Everything.
(it doesn’t. It changes only some things, but bear with me)
I already discussed how the pandemic changes priorities for CPaaS vendors. This new development is going to make things more of a mess.
Why now?Amazon Chime SDK was already announced and launched close to the end of 2019. They already have customers and success stories under their belt. Why am I just now getting to look at how IaaS vendors are changing the market?
Probably a bit because I am doing the update to my WebRTC API platforms report this month. But also because of Microsoft’s announcement of their Azure Communication Services.
Amazon Chime SDKAmazon started the work to video communications by the introduction of Chime a few years back. Chime is an enterprise communication service (in the UCaaS space), which is akin to Zoom, Google Meet and Microsoft Teams. It enables companies to communicate internally and externally via video and voice with a better set of collaboration tools than just phone calls.
For some time now Amazon Chime was also offered as a whitelabel solution that vendors could “make their own” and integrate it with their service. But it doesn’t allow for much flexibility in terms of the workflow, business logic and user authentication. This has led Amazon to introduce the Amazon Chime SDK.
The Chime SDK is one rung lower in the stack. It enables a developer access to the logical building blocks of communications, offering a pure communication API that can be used to connect to any other service. A direct competitor to the other CPaaS vendors offering video capabilities.
What Chime SDK did to really disrupt the market was lower the price point per minute. It comes at a rate of $0.0017 per user per minute. Twilio answered with its own price drop in September 2020:
A 60% reduction in Twilio Programmable Video price pointsThe new rates are still above the Amazon Chime SDK price points, but they are 40% their previous price points.
It should be noted that peer-to-peer calling available in Twilio Programmable Video is at $0.0015, lower than the Amazon price, but of a slightly different service and feature set.
What Amazon is “selling” here? The AWS story. From the main Chime SDK page:
AWS Lambda is already there. Connectivity to other AWS services are also part of the bigger spiel.
Azure Communication Services (AKA ACS)Microsoft just announced Azure Communication Services in a public preview. This is a full CPaaS offering that includes Video, Chat, SMS and Telephony calling. The interesting tidbits alluded to in the announcement:
- Azure enabled, with all the knobs and pieces to connect it to other Azure services; along with the security and compliance of the Azure cloud
- Connectivity with Microsoft Teams, which isn’t available yet in the public preview
Watch that video above. There’s a visual explanation of remote visual assistance. I’d never think of explaining embedded video communications or programmable video communications this way – because I am in the industry for this long. What Micsoroft is doing here is educating the market in the most basic way possible. Something we were missing in our market without even knowing it. This type of an approach can work well in the enterprise space, which hasn’t adopted such services in droves just yet.
What makes this so interesting is this:
- Microsoft is the only CPaaS vendor who has a huge UCaaS offering. Huge as in up to 5B (or more) meeting minutes a day. Starting off with the same underlying scalable infrastructure means resilience, reliability and scale
- This is part of Azure and not tied to Teams. Like the AWS Chime SDK offering, the tie in with machine learning in their compute cloud brings value to developers using Azure already
- Microsoft has Office as another huge asset. If they can make the connection to it here, this is another great differentiator
On pricing, Microsoft was a bit more traditional and less bold than Amazon, sticking to the $0.004/minute price point the market seems to have adopted.
The new model for Video CPaaS?Even before Amazon and Microsoft joined this space, there were two objectives you could see in the mid-term and long-term roadmap for video CPaaS vendors:
- Add support for machine learning
- Introduce higher level of abstraction
These map where the new video CPaaS is headed, and the fact that Amazon and Microsoft both come with this “built-in” will accelerate things further.
Machine LearningEveryone’s doing machine learning these days, and it is part of the future of communications and WebRTC.
Amazon Chime SDK will be offering their noise suppression capabilities. Connect to Kinesis and enable access to all their other machine learning services.
Microsoft in their launch already mentioned Azure Cognitive Services as something that plays/will play nice with ACS.
Other CPaaS vendors are figuring out their way in this space as well, but part of their offering is usually how to gain access to the media for… sending it to the cloud for machine learning analysis. That cloud is going to be AWS and Azure more often than not. Being in that cloud to begin with is going to be an advantage for these cloud vendors and their CPaaS offerings.
Also remember that cloud vendors live and breath machine learning already. CPaaS vendors? Less so.
Higher abstractionsEveryone in this space is talking about simplicity now.
How can I get developers to do their work in hours versus days. Days versus weeks. Weeks versus… no… weeks is too long already.
While this is unrealistic for a full fledged, polished service, it is something that works well towards an MVP or a first stab at a ready product.
Some do this by offering open source or reference applications on top of their CPaaS APIs. Others by offering this as a set of ready-made and highly configurable widgets.
It doesn’t seem like anyone has cracked the code of what is needed here, but the growing focus shows there’s something missing. Especially if we want developers to need to know less about WebRTC and media routing and more about their application logic.
I think that Amazon and Microsoft joining this market will speed up the efforts in this domain, as companies search for differentiation and quick onboarding.
Why telephony is dying and communication is growingBoth Amazon and Microsoft are leading here with video, adding chat and telephony later. Later can be immediately after the initial launch, but it is still later.
In the past it made sense to do the opposite. Lead with PSTN and SMS as money makers, and add WebRTC voice and video, waiting for them to grow in adoption.
Taking the opposite approach shows where the future of consumption is.
WinnersWho are the winners when CPaaS is done by the cloud vendors?
UsersIf cloud vendors are joining this game, it means there’s enough $$$ in this market to make it interesting, which means more users are consuming such services.
The market education that these cloud vendors are capable of doing and their reach is higher than the other CPaaS vendors, excluding maybe Twilio. This will end up with more enterprises and businesses offering such services and end users using them.
Tier 1 cloud vendorsAmazon and Microsoft. Their timing couldn’t have been better.
If I haven’t known that Bill Gates is causing the pandemic so he can chip us all when his vaccine comes to market and causes all birds to fall from the sky due to 5G, I’d might end up saying that Jeff Bezos is to blame because he wanted the Chime SDK to grow in market share.
In all seriousness though, this gets both Amazon and Microsoft in front of the developers that use them for additional types of services that these developers are going to consume.
Smaller cloud vendorsDigital Ocean and Oracle.
Why are they winners? I am not sure how Twilio can continue running Programmable Video on top of AWS and compete with AWS Chime SDK on price and geographic spread.
Same for the other CPaaS vendors who might be using AWS or Azure. They will be thinking hard if they want to keep their media stacks on these platforms or move them elsewhere. They can move them to Google Cloud, but Google just might introduce the same capabilities and become a competitor. Next in line will be Digital Ocean and Oracle, both cloud vendors that are carrying real time media traffic already. If I were a sales person there, I’d pick up the phone today and call the CPaaS vendors one after the other…
DevelopersA definite win. More choice. In clouds they already use. With a price war coming up.
What’s there to lose?
LosersWho are the losers when CPaaS is done by the cloud vendors?
CPaaS vendorsThey now have more competition. And not from smaller startups, but rather from the leading cloud vendors.
Cloud vendors already cater to developers, and a larger audience of developers.
Things are going to get interesting for these vendors, as they need to rethink differentiation, their own infrastructure and their pricing.
TwilioTwilio is the leading CPaaS vendor today.
They are using AWS. Everywhere.
This is definitely hurting them and will hurt them more moving forward.
Out of all the threats to Twilio, having cloud vendors competing head to head with them was the biggest one, and it is now happening.
It made sense for someone like Amazon to acquire them and use them as the communication stack for AWS. now it won’t happen.
Maybe Google will acquire them, though this seems far fetched to me.
Google3 leading cloud vendors.
- Amazon
- Now has AWS Chime SDK
- Lots of adjacent services for developers
- Microsoft
- Now with Azure Communication Services
- Lots of adjacent services for developers
- Owner of Microsoft Teams, used as the underlying technology and media stack, with the ability to connect ACS to Teams if and when needed
- Got Office 365 as another huge asset
- Google
- Nothing in communication APIs
- Owner of Google Meet and Google Duo
- Leveraging RCS with carriers and in Android
- Has G Suite and Android as huge assets
- Has Chrome and Chrome books as assets
- Did I say no communication APIs?
Google is left behind in its communication APIs for developers, which is sad, considering they are the main driving force behind WebRTC.
I wonder if and when will Google close this gap.
DevelopersThis will definitely rattle the existing vendors. Some of them might not make it through. So choice will again get a wee bit limited as this plays out.
While cloud vendors are great, their support isn’t the best. They tend to offer support to the smaller developers and companies through third parties and not directly, so there’s going to be less of that available. And that for a domain that is still very complex in its nature.
Developers both win and lose from this development.
Updating my WebRTC API reportThere’s a lot of change in the CPaaS domain. I mostly look at these vendors from a WebRTC prism, but not only.
This past month I’ve been working on updating my Choosing a WebRTC API platform report. I had a lot of briefings with the various vendors, researched their websites, added vendors, removed vendors. Grueling work.
The updated report will be published during October. It will include ~25 vendors, and touch everything from build vs buy, selection KPIs, vendor listing and pricing.
If you are looking to understand this domain better or need to select one vendor over another for an important project, then this report is for you. From today and until the report gets published, there’s a wee bit over 25% discount using coupon code API2020LAUNCH. Purchasing the report now will give you access to the current report as well as the fresh update once it is available.
The post Cloud giants joining the WebRTC API game. How is that changing the CPaaS landscape? appeared first on BlogGeek.me.
What should CPaaS providers do today to prepare for the “post pandemic”?
The pandemic is changing everything. CPaaS providers need to change their priorities and focus as well.
It is around this time of the year that I start thinking about where the CPaaS market is headed.
Mention last year’s articles on the future of CPaaS (this one was pre-pandemic) and on how CPaaS vendors differentiate (also pre-pandemic, and so “last year”).
The pandemic is an epochal event. It caught the CPaaS industry somewhat ready, with gaps found in their video offerings. Behind the pandemic, a few other market changes are taking shape, affecting how CPaaS providers need to plan ahead.
I’d like to look at a few of these trends and outline what I see as the basis of CPaaS competition for the future.
CPaaS features map CPaaS marketecture and features mapThe diagram above shows the CPaaS features map. It is a kind of a marketecture diagram of the various bits and pieces that make up CPaaS.
I’ve layered it from Infrastructure, through Communications Building Blocks and Higher Abstraction to the Simplified Runtime domain. While not all CPaaS vendors will fill all building blocks in this map, they all see it in front of them one way or another.
Here are a few things to note:
- I’ve decided not to place Email or IoT in here though I could without much effort
- The importance of each block will be different for different customers and will change over time. The pandemic certainly changed priorities shifting them towards Video for example
- I am using the term Studio, though Flow is the one that is used by most of Twilio’s competitors
- ML stands for Machine Learning and it has its place throughout the CPaaS product stack. More on that later
If I had to map priorities for 2021, I’d probably create this heatmap:
CPaaS areas of investment in 2020-2021 The pandemic and CPaaS vendorsIn many ways, the pandemic is accelerating the need for CPaaS providers. The world switched en masse from one of physical interactions to a virtual one. This, in turn, exposed a few aspects in the CPaaS market.
Digital transformation fast forwardThe image above circulated on Twitter some time in March-April this year. It is spot on.
Digital transformation is here and it is here to stay. It came about a few years faster than expected and to get by, companies are relying more on communications and a lot of it comes today from vendors who use CPaaS or by developing the solutions needed on top of CPaaS platforms.
The thing is, in many cases, the increase is also catching businesses off guard, with call centers and support teams being overwhelmed with incidents. And that at a point in time where everyone is forced to work from home – including the call center agents.
This in turn, increases the requirements around technologies that assist in automation of processes and communication channels. Call deflection and agent assist solutions are taking center stage. This changes a bit how CPaaS vendors need to treat communication APIs, and especially what these APIs need to enable.
Are we looking now for more or less Uber-like solutions of matching a customer to a service provider? Or are we more about getting hold of the interaction’s content in real time and injecting insights into it, with or without a human agent?
I don’t have the answers, but I have a feeling that they are different than they were 9 months ago.
CPaaS vendors totally missed video Video growth was unexpected, catching most CPaaS vendors unpreparedYap. We had CPaaS vendors doing video. A few of them. And they’re just fine. Up until the point that video becomes important for everyone and that totally new use cases pop up in our market on almost a daily basis.
Zoom doesn’t mean a magnifying glass anymore. Nor is it talking about getting a closer look.
During the pandemic?
- Daily officially launched. And raised money
- Dolby.io launched
- Agora raised some $350M in their IPO
All of the above? Focus on video communications. None of them have any telephony roots or strong telephony capabilities. No phone numbers or SMS capabilities to speak of.
AWS decided it would be nice to join the frey, so they launched their own Chime SDK. With price points that challenge the existing players.
Twilio decided this month to lower their video price points. Cutting them down by some 60%.
8×8’s Jitsi is coming up with its own managed video API service, pricing it around MAU as opposed to the more common per minute pricing.
There’s a minor price war coming up around video APIs. It will be interesting to see how this plays out.
Lack of WFH tooling in CPaaSWFH = Work From Home
Working from home isn’t just working from a different locationWelp… we’ve built all these nice communication services, but we’ve designed them mostly to work for the office.
On premise call centers moved to the cloud by adopting CPaaS, which is great, but the workforce itself still came to the office. All calls and communications took place from a controlled and managed environment.
The pandemic has forced call centers of tens of thousands of agents to stop coming to the office while continuing to work. From home. How do call center managers know anything about the environment of the home employee? How can he make sense of the quality of experience his agents and his customers are getting?
From the interest we see at testRTC in our qualityRTC service, there’s a real gap there.
Call this self promotion, but it is one of many areas where CPaaS vendors need to improve in order to offer a suitable WFH solution. Giving APIs is nice. Giving backend network insights and quality related dashboards is nice. Giving pre-call tests capabilities is nice. But I am not sure it is enough anymore.
Other aspects of WFH that aren’t catered for by CPaaS vendors? The need for noise suppression and background blurring/removal – to fit into the current work environments of call center agents and other workers.
The pandemic will pass, but digital transformation won’t Are we really in a new normal?It was supposed to be a quick 2 months thing. Maybe 6. A year tops.
Then came Google and Facebook (not governments, because they can’t seem to be so realistic and pessimistic with their citizens), and simply let anyone work from home at least until July 2021. At least.
Fujitsu? Decided to cut office space by 50% in 3 years as the new normal.
LivePerson, an Israeli company with 1,300 employees decided to give up on its offices altogether and go 100% WFH. This saves money and apparently most employees prefer it while management doesn’t see enough of a degradation in production output.
This obviously isn’t the case everywhere. In a recent interview with the The Wall Street Journal, Reed Hastings, CEO of Netflix had this to say about remote work:
“I don’t see any positives. Not being able to get together in person, particularly internationally, is a pure negative. I’ve been super impressed at people’s sacrifices.”
To some degree, he is correct. It greatly depends on the type of industry and company.
Dean Bubley says it best about business events:
In-person business events will rise again, although I’m less certain about office work.
[…]The #NewNormal will not be 100% remote. Once a vaccine is available, I hope that it isn’t even 50% #WFH.
My wife is a Pilates and Salsa dance teacher. She needs to work remotely now from time to time, with Zoom and recorded lessons. Her students? They’re fine with it, but whenever they can come over or do a face-to-face-in-the-flesh lesson – they’d take the opportunity.
This means that whatever it is CPaaS vendors are seeing as requirements may well stay and stick with them for the long run. What we have now isn’t a new normal, but there’s no going back to the old normal either.
3 pillars of CPaaS competition and differentiation in 2021When I had to decide what are the main areas of investment for CPaaS when it comes to differentiation and competition towards 2021, I came to these 3 domains: machine learning, video and diagnostics.
There are two reasons why I chose these domains:
- Renewed focus on IP based communications. WebRTC and VoIP are becoming paramount to the growth and future of CPaaS. SMS and phone numbers are great money makers, but they’re not the future. The pandemic threw us a few years into the future, accelerating this trend
- Competing with in-house development. Phone numbers are complicated. Not because they are technically complex, but because they require haggling and contracting with multiple carriers around the globe, which gives an immediate advantage to CPaaS providers. With WebRTC that doesn’t exist anymore, and in-house becomes a bigger competitor to CPaaS providers. The domains below will increase the gap between build and buy for potential clients and also increase the perceived value of a solution
Noise suppression. Background replacement. Super resolution. Bandwidth estimation. Packet loss concealment. …
All these are algorithms in the media processing domain affecting the user experience in communications. Like everything else they are now shifting towards using a lot more machine learning than in the past.
The current forerunner in importance and mindshare is noise suppression, with a lot of partnerships and M&A activities around it.
When it comes to machine learning in media quality, what are CPaaS vendors doing today?
Almost nothing at all.
- Dolby.io have noise suppression and other audio enhancements
- Agora actively invests in machine learning. They’ve spoken about it at Kranky Geek multiple times, around super resolution and video encoding
- AWS added noise suppression to Chime, which is most likely part of the new Chime SDK. They even won an award for their noise suppression capabilities
The rest? Not doing much about machine learning, researching or doing bots.
This cannot last.
We’ve already seen how WebRTC is being unbundled for the purpose of differentiation. That differentiation will come in the form of optimizations, mostly done by use of machine learning.
What will vendors do? Especially when we see the leading UCaaS vendors actively investing in machine learning media processing capabilities? This sets the bar to what a communication service needs to look like, and without such capabilities, why should I as a developer use that CPaaS vendor?
2# – Video, Video, Video Tony Robbins going virtual. Is this a CPaaS implementation???Did I already say we’re in the year of the video?
It is.
A billion have been indoctrinated over a period of 1 month this year on how to use Zoom. don’t nitpick me on the exact number please. My mother now users Zoom in her daily life of a variety of activities, including a book reading club she joined
Many CPaaS vendors had video capabilities but they usually amounted to 1:1 interactions or small group sizes. There isn’t a day going by where I don’t get a new requirement from someone that CPaaS providers can’t cater for today. Many of these are in the domain of broadcasts and large groups (100 or more participants). Using CPaaS for them today feels like hacking at best. Impossibly challenging at most.
There are many areas where CPaaS providers are lacking when it comes to video. Here are the few that immediately come to mind:
- What we are seeing is a rapid growth in the feature set and requirements of video centric use cases. These needs to be addressed. As a simple example, how do you do a live session with one presenter streaming to a large audience and the audience in turn sending their own video to the presenter, so that the presenter sees them all at the same time (or can alternate between them)?
- There’s a blurring of the lines between voice, video, broadcast and streaming. There’s a need to seamlessly switch from one to the other. Broadcast and streaming comes today predominantly from non-CPaaS vendors. There’s a growing pressure for these to be wrapped into CPaaS for interactive use cases
- Price points of video services need to be adjusted. With the change brought by AWS Chime SDK, and the pricing model of 8×8 JaaS, there are bound to be changes for other CPaaS vendors. This is imperative, especially when build vs buy decisions rely so heavily on back of the napkin calculations of minutes use multiplied by a static number
- Location of data centers and the latency brought about due to it. Most CPaaS vendors have 10 or less data centers they operate from. Now that everyone is using video, this just isn’t enough. It might be nice for voice calls in call centers, but video calls the world over are different – and they take place a lot more locally within regions and countries now, so having data centers closer to users is becoming more important than ever
The investment in video communications in all its facets will be important to stay competitive in this space.
#3 – Diagnostics and analyticsIt is great that you can communicate, but what happens when things go haywire?
In my recent round of updates I am doing for my Choosing a WebRTC API Platform report, many of the vendors made sure I know they have a dashboard for quality and network monitoring. Different vendors give it different names, but they all understood that unlike telephony, there’s a need for insights here, especially since networks are unmanaged.
It isn’t about me as a client understanding if the CPaaS vendor is doing a good job, but rather about me understanding my users’ networks and experience. Current dashboard solutions will need to evolve further to give the insights their customers are looking for.
Didn’t you miss anything?In my future of CPaaS article from last year I mentioned a few additional trends. Some of them have been reiterated here, though from a different angle and with a different narrative that fits better with the changing times.
There were three topics that weren’t mentioned here yet, and I want to give them a bit of room and explain where I see them in 2021 with CPaaS.
nocode / low codeStill a thing. Serverless, Flow, Zapier integration, drag and drop tools. All there. All needed.
For the most part, CPaaS vendors seem to be content with the current state of affairs and the current tools they have. Investment in this domain in 2020 didn’t yield anything vastly different, new or interesting.
The domain of nocode is still relevant and interesting. For now, it seems to be mostly limited to the telephony (and voice) aspects of CPaaS.
CCaaS and UCaaSThe lines are blurring elsewhere as well. Areas of IoT (below), messaging and notifications, live streaming – are all suitable adjacencies for expansion of CPaaS vendors.
The largest areas though are CCaaS and UCaaS: contact centers and unified communications
Acronyms will be tricky here. So bear with me.
- CCaaS and UCaaS are investing heavily in ML. A lot of it now is around #WFH
- CPaaS is going up the foodchain, mainly after CCaaS. Some do it directly (Twilio Flex), others pivoting sideways to conversations (MessageBird Omnichannel Chat Widget)
- UCaaS is vying towards CPaaS, introducing their own APIs and even CPaaS offerings
In another world, just next by, other SaaS solutions are blurring their lines. Gist (the chat widget I am using on my WebRTC course site) announced to its customers that it is releasing a full fledged CRM. From conversations to CRM.
CRMs in turn, can use CPaaS vendors directly to build up their own CCaaS offering. With the higher level abstractions geared towards customer engagement, CPaaS vendors now offer a simple route for CRMs in this direction.
This will continue, though I don’t see it as direct competition or real differentiation within the CPaaS domain itself.
IoTTwilio seems to be the only CPaaS vendor investing in the Internet of Things. It acquired Electric Imp earlier this year. The acquisition wasn’t made with much fanfare, as this isn’t the main focus of Twilio and the current market is interested less in IoT than it is in video calls.
Is IoT part of CPaaS? Time will tell.
I believe that it is, but for now, only Twilio seems to be investing in that domain where none of its other immediate CPaaS competitors have the appetite for it. This will not change in the next couple of years as focus for CPaaS is elsewhere at the moment.
Updating my WebRTC API reportThere’s a lot of change in the CPaaS domain. I mostly look at these vendors from a WebRTC prism, but not only.
This past month I’ve been working on updating my Choosing a WebRTC API platform report. I had a lot of briefings with the various vendors, researched their websites, added vendors, removed vendors. Grueling work.
The updated report will be published during October. It will include ~25 vendors, and touch everything from build vs buy, selection KPIs, vendor listing and pricing.
If you are looking to understand this domain better or need to select one vendor over another for an important project, then this report is for you. From today and until the report gets published, there’s a wee bit over 25% discount using coupon code API2020LAUNCH. Purchasing the report now will give you access to the current report as well as the fresh update once it is available.
The post What should CPaaS providers do today to prepare for the “post pandemic”? appeared first on BlogGeek.me.
ML in WebRTC: The noise suppression gold rush
Communication vendors are waking up to the need to invest in ML/AI in media processing. The challenge will be to get ML in WebRTC.
Two years ago, I published along with Chad Hart a report called AI in RTC. In it, we’ve reviewed the various areas where machine learning is relevant when it comes to real time communications. We’ve interviewed vendors to understand what they’re doing and looked at the available research.
We mapped 4 areas:
- Speech Analytics
- Voicebots
- Computer Vision
- RTC Quality and Cost Optimization
That last area was tricky. Almost everyone was using rule engines and heuristics at the time for all of their media processing algorithms and only a few made attempts to use machine learning.
My argument was this:
At some point, applying more heuristics to media processing algorithms loses its appealThere’s so much we can do with rule engines and heuristics. Over time, machine learning will catch up and be better. We are now at that inflection point. Partially because of the technology advances, but a lot because of the pandemic.
ML in media processing is challengingWhen looking at machine learning in media processing, there’s one word that comes to mind: challenging
Machine learning is challenging.
Media processing is challenging.
Together?
These are two separate and far apart disciplines that need to be handled.
The data you look at is analog in its nature, and there’s often little to no labeled data sets to work with.
A few of the things you need to figure out here?
- How do you find machine learning engineers, or whatever they are called in their titles this day of the week?
- Do these engineers know anything about media processing? How do you get them up to speed with this technology? Or is it the other way around? Getting media engineers trained in machine learning
- Can you generate or get access to a suitable data set to use? Do you even have access to enough data?
- Where do you focus your efforts? Audio or video? Maybe just network? Should you go for server side implementation or client side one? What about model optimizations?
- When do you deem your efforts fruitful? Ready for production?
This isn’t just another checkmark to place in your roadmap’s feature list. There’s a lot of planning, management effort and research that needs to go into it. A lot more than in most other features you’ve got lined up.
The noise suppression gold rushIf I had to pick areas where machine learning is finding a home in communications, it will be two main areas:
- Video background processing (more on that at some future point in time)
- Noise suppression
Both topics were always there, but took centerstage during the pandemic. People started working from weird places (like home with kids) and you now can’t blame them. One of the best games I play in workshops now? Checking who’s got the most interesting room behind him…
Video background is about stopping me from playing. Noise suppression is about you not hearing the lawn mower buzzing 16 floors below me, or the all-too-active neighbor above me who likes to home renovate whenever I am on a call – with a power drill.
How I think my neighbor looks like whenever I am on a conference callThis need has led to a few quick wins all around. The interesting 3 taking place in the domain of WebRTC (or near enough) are probably the stories about Google Meet, Discord/Krisp and Cisco/BabbleLabs.
Google Meet Google Meet built its own noise suppression technologyIn June, Serge Lachapelle, G Suite Director of Product Management was “called to the flag” and was asked to do a quick interview for The Verge on Google Meet’s noise suppression. Serge was once the product manager for WebRTC at Google and moved on to Google Meet a few years back.
You can watch the short interview here:
The gist of it?
- Google decided to implement it in the cloud
- They use “secure” TPUs for that (Tensorflow Processing Units, a specialized chip in the Google Cloud for machine learning workloads)
- The feature is optional. It can be enabled or disabled by the user
- Noises it cancels are almost arbitrary. It is something that is really hard to define as initial requirements. It is also something that will be fine tuned and tweaked over time by Google
As I stated earlier, Google isn’t taking any prisoners here and contributing this back to the community freely as part of WebRTC. They are making sure to differentiate by making sure their machine learning chops are implemented outside of the open source WebRTC library. This is exactly what I’d do in their place.
Discord Discord “bought” its way to noise suppression by partnering with KrispKrisp is one of the few vendors tackling machine learning in media processing and doing that as a product/service and not a feature. They’ve been at it for a couple of years now, and things seems to be going in their favor this year.
Krisp managed to do a few things:
- Focus on noise suppression. They started “all over the place” with voice related media algorithms, and seem to be finding product-market-fit in noise suppression
- Won a deal/partnership with Discord
- Got their technology to work inside the browser (see here)
The Discord story was first published in April on Discord’s blog. Noise suppression was added in beta to the Discord desktop app. Was that done using the browser technology used in Discord’s Electron app or by the native implementation that Krisp has is an open question, but not the most relevant one.
Three months later, in July, Discord got noise suppression into iOS and Android. This was also done using Krisp and with a spanking short video explainer:
Ongoing successHere are my thoughts here:
- Adding this to mobile means they got positive feedback on the desktop integration
- Especially considering how they phrased it:
As we continue to improve voice chat, Krisp is an integral part of making Discord your place to talk. No matter how stressful the world around us may be, Krisp is here to help every one of our 100 million monthly active users feel more connected to our far-away friends.
- 100 MAU is what Discord now has, and this is a vote of confidence in Krisp and in ML-based noise suppression technology
- Discord shouts to the world that they are using Krisp. Something not many companies do for their suppliers
- This may mean that they got this on the cheap (or free)
- Or it means that they are cozying up to Krisp
My read of it? Krisp might be acquired and gobbled up by Discord to make sure this technology stays off the hands of others – if that hasn’t happened already – just look at this page – https://krisp.ai/discord/ (and then compare it to their homepage).
Cisco Cisco gobbled up BabbleLabs to own noise suppression technologyIn the case of Cisco, the traditional approach of reducing risk by acquiring the technology was selected – acquihiring.
Last week, Cisco issued a press release of their intent to acquire BabbleLabs.
BabbleLabs was in the same space as Krisp. A company offering machine learning-based algorithms to process voice. The main algorithm there today as we’ve seen is noise suppression. This is what Cisco were looking for and now they will have it inhouse and directly integrated into WebEx.
Cisco devices not to self-develop. They also decided to own the technology. The reasons?
- Google owns it
- Zoom has its own implementation
- That left… WebEx
Will BabbleLabs stay open? No.
In his recent post about the acquisition, Chris Rowen, CEO of BabbleLabs, explains what lead to the acquisition and paints a colorful future. The only thing missing in that post is what about existing customers. The answer is going to be a simple one: They will be supported until the next renewal date, when they will simply be let go.
A win to Krisp. If it isn’t in the process of being acquired itself already.
Who’s next?This definitely isn’t the end of it. We will see more vendors taking notice to this one and adding noise suppression. This will happen either through self-development or through the licensing of third party solutions such as Krisp.
The challenge with these third party solutions is that they feel more like a feature than a product or a full fledged service. On one hand, everyone needs them now. On the other hand, they need to be embedded deep in the technology stack of the vendors using them. The end result is relatively small companies with a low ceiling to their potential growth (=not billion dollar companies). This puts a strain on such companies, especially if they are VC backed.
On the other hand, everyone needs noise suppression now. Where do they go to buy it? How do they build it?
Noise suppression is just the beginningNoise suppression is just the beginning here. In the workshop I did last month on WebRTC innovation and differentiation, I’ve taken the time to focus on this. How machine learning is now finding a place in bringing differentiation to the actual communication. Noise suppression was one of the topics discussed, with many others.
There were 3 main areas that we will see growing investment in:
- Voice treatment – noise suppression, packet loss concealment, voice separation, etc
- Video treatment – video compression, super resolution, etc
- Background blur/replacement – I am placing it on its own, as it seems to be the next big thing
Each of these domains has its own set of headaches and nuances.
Server, native or browser? Should you employ ML in WebRTC in the cloud or on the edge?This is a big question.
If you look at the examples I’ve given for noise suppression:
- Google Meet chose cloud
- Discord is native and browser
- WebEx is native as far as I can tell
Going for native or browser means you’re closer to the edge and the user. You can do things faster, more efficiently and with a lower cost to you (you’re practically employing the user’s device to bear the brunt of running the machine learning inference algorithm). That also means you have less resources for other things like the actual video and you’re limited in the size of the model you can use for your algorithm.
Cloud means a central place where you can do training, inference, A/B testing, etc. It is probably easier to maintain and operate in the longer run, but it will add some delay to the media and will definitely cost you to run at scale.
Each company will choose differently here, and you may see a company choosing for one algorithm to run it in the cloud and for another to run on the edge.
Are you planning for this ML/AI future?Machine learning and artificial intelligence is in our future. Both in the communication space and elsewhere. It is finally coming also to media processing directly. In a few years, it will be a common requirement from services.
Are you planning for that in any way?
Do you know how you’re going to get there?
Will you be relying on third parties or on your own inhouse technology for it?
There are no open source solutions at the moment for any of it. At least not in a way that can be productized in a short timeframe.
If you need assistance with answering these questions, then check my workshop. It is recorded and available online and it is more relevant than ever.
WORKSHOP: WebRTC Innovation and Differentiation in a Post Pandemic World
The post ML in WebRTC: The noise suppression gold rush appeared first on BlogGeek.me.
WebRTC unbundling: the beginning of the end for WebRTC?
2020 marks the point of WebRTC unbundling. It seems like the new initiatives are the beginning of the end of WebRTC as we know it as we enter the era of differentiation.
Life is interesting with WebRTC. One moment, it is the only way to get real time media towards a web browser. And the next, there are other alternatives. Though no one is quite announcing them the way they should.
We’re at the cusp of getting WebRTC 1.0 officially released. Seriously this time. For real. I think. Well… maybe.
Towards differentiationIf I were to chart our path through this crazy world of WebRTC, it would look something like this:
2020 marks the beginning of the differentiation stage for WebRTCTowards the end of 2019, and at greater force during the pandemic, we’ve seen how the future of WebRTC looks like. It is all about differentiation.
Up until now, all vendors had access to the same WebRTC stack, as it is implemented by Google (and the other browser vendors), with the exact same capabilities in the browser.
No more.
I’ve alluded to it in my article about Google’s private WebRTC roadmap. Since then, many additional signals came from Google marking this as the way forward.
Today, there are 2 separate WebRTC stacks – the one available to all, and the one used internally by Google in native applications. While this is something everyone can do, Google is now leveraging this option to its fullest.
The interesting thing that is happening is taking place somewhat elsewhere though. WebRTC is now being unbundled so that Google (and others) don’t need to maintain two separate versions, but rather can have their own “differentiation” implemented on top of “WebRTC”.
Unbundling WebRTCAt this point, you’re probably asking yourselves what does that mean exactly. Before we continue, I suggest you watch the last 15 minutes from web.dev LIVE Day Two:
That’s where Google is showing off the progress made in Chrome and what the future holds.
The whole framing of this session feels “off”. Google here is contemplating how they can bring a solution that can fit Zoom, that when 99% of all vendors have figured out already how to be in the browser – by using WebRTC.
The solution here is to unbundle WebRTC into 3 separate components:
The components set to unbundle WebRTC- WebTransport – enables sending bidirectional low latency UDP-like traffic between a client and a “web server”, which in our context is a media server
- WebCodecs – gives the browser the ability to encode and decode audio and video independently of WebRTC
- WebAssembly – a browser accelerator for running code and an enabler for machine learning
While these can all be used for new and exciting use cases (think Google Stadia, with a simpler implementation), they can also be used to implement something akin to what WebRTC does (without the peer-to-peer capability).
WebTransport replaces SRTP. WebCodecs does the encoding/decoding. WebAssembly does all the differentiation and some of the heavy lifting left (things like bandwidth estimation). Echo cancellation and other audio algorithms… not sure where they end up with – maybe inside WebCodecs or implemented using WebAssembly.
What comes after the unbundling of WebRTC?This isn’t just a thought. It is an active effort taking place at Google and in standardization bodies. The discussion today is about enabling new use cases, but the more important discussion is about what that means to the future of WebRTC.
As we unbundle WebRTC, do we need it anymore?
With Google, as they have switched gears towards differentiation already, it is not that hard to see how they shift away from WebRTC in their own applications:
Google Stadia Does Stadia has a reason to use WebRTC?Google Stadia is all about cloud gaming. WebRTC is currently used there because it was the closest and only solution Google had for low latency live streaming towards a web browser.
What does Google Stadia need from WebRTC?
- The ability to decode video in real time in the browser
- Send back user actions from the remote control towards the cloud at low latency
That’s a small portion of what WebRTC can do, and using it as the monolith that it is is probably hurting Google’s ability to optimize the performance further.
Sending back user actions were already implemented in Stadia on top of QUIC and not SCTP. That’s because Google has greater control over QUIC’s implementation than it does over SCTP. They are probably already using an early implementation of WebTransport, which is built on top of QUIC in Stadia.
The decoding part? Easier to just do over WebTransport as well and be done with it instead of messing around with the intricacies of setting up WebRTC peer connections and maintaining them.
For Stadia, unbundling WebRTC will result moving away from WebRTC to a WebTransport+WebCodecs combo is the natural choice.
Google Duo & Google Meet Meet & Duo. Will moving away from WebRTC improve their competitiveness?For Duo and Meet things are a bit less apparent.
They are built on top of WebRTC and use it to its fullest. Both have been optimized during this pandemic to squeeze every ounce of potential out of what WebRTC can do.
But is it enough?
Differentiation in WebRTCGoogle has been adding layers of differentiation and features on top and inside of WebRTC recently to fit their requirements as the pandemic hit. Suddenly, video became important enough and Zoom’s IPO and its huge rise in popularity made sure that management attention inside Google shifted towards these two products.
This caused an acceleration of the roadmap and the introduction of new features – most of them to catch up and close the gap with Zoom’s capabilities.
These features ranged from simple performance optimizations, through beefing up security (Google Duo doing E2EE now), towards machine learning stuff:
- Proprietary packet loss concealment algorithm in native Duo app
- Cloud based noise suppression for Meet
- Upcoming background replacement for Meet
- …
Can Google innovate and move faster if they used the unbundled variant? Instead of using WebRTC, just make use of WebTransport+WebCodecs+WebAssembly?
What advantages would they derive out of such a move?
- Faster time to market on some features, as there’s no need to haggle with standardization organizations on how to introduce them (E2EE requires the introduction of Insertable Streams to WebRTC)
- Google Meet is predominantly server based, so the P2P capability of WebRTC isn’t really necessary. Removing it would reduce the complexity of the implementation
- More places to add machine learning in a differentiated way, instead of offering it to everyone. Like the new WaveNetEQ packet loss concealment was added outside of WebRTC and only in native apps, it could theoretically now be implemented without the need to maintain two separate implementations
If I were Google, I’d be planning ahead to migrate away from WebRTC to this newer alternative in the next 3-5 years. It won’t happen in a day, but it certainly makes sense to do.
Can/should Google maintain two versions of WebRTC?Today, for all intent and purpose, Google maintains two separate versions of WebRTC.
The first is the one we all know and love. It is the version found in webrtc.org and the one that is compiled into Chrome.
The other one is the one Google uses and promotes, where it invests in differentiation through the use of machine learning. This is where their WaveNetEQ can be found.
Do you think Google will be putting engineers to improve the packet loss concealment algorithm in the WebRTC code in Chrome or would it put these engineers to improve its WaveNetEQ packet loss concealment algorithm? Which one would further its goal, assuming they don’t have the manpower to do both? (and they don’t)
I can easily see a mid-term future where Google invests a lot less in WebRTC inside Chrome and shifts focus towards WebTransport+WebCodecs with their own proprietary media engine implementation on top of it powered by WebAssembly.
Will that happen tomorrow? No.
Should you be concerned and even prepare for such an outcome? That depends, but for many the answer should be Yes.
The end of a level playing field and back to survival of the fittestWebRTC brought us to an interested world. It leveled the playing field for anyone to adopt and use real-time voice and video communication technologies with a relatively small investment. It got us as far as where we are today, but it might not take us any further.
Recent changes marks the shift from a level playing field in WebRTC towards survival of the fittestFor this to be sustainable, browser vendors need to further invest in the quality of their WebRTC implementations and make that investment open for general use. Here’s the problem:
Apple (Safari)Doesn’t really invest in anything of consequence in WebRTC.
- They seem to care more about having an HEVC implementation than in getting their audio to work properly in mobile Safari in WebRTC
- To date, they have taken the libwebrtc implementation from Google and ported to work inside Safari, making token adjustments to their own media pipelines
- I am not aware of any specific improvements Apple made in Safari’s WebRTC implementation to quality via the media algorithms used by libwebrtc itself
Apple cares more about FaceTime than all of that WebRTC nonsense anyways…
Mozilla (Firefox)Actually have a decent implementation.
- While Firefox uses libwebrtc as the baseline, they replaced components of it with their own
- This includes media capturer and renderer for audio and video
- They have invested a lot in improving the audio pipeline in Firefox, which affects quality in WebRTC
Their latest Edge release is Chromium based.
- They aren’t doing much at the moment in the WebRTC part of it is far as I am aware
- They could improve the media pipeline implementation of Chromium (and by extension Edge) for Windows 10
- But…
- Do they have an incentive?
- Would they contribute such a thing back to Google or keep it in their Edge implementation?
- Would Google take it if Microsoft gave it to them?
And then there’s Microsoft Teams, which offers a sub par experience in the browser than it does in the native application. All of the investment of Teams is going towards improving quality and user experience in the app. The web is just an afterthought at the moment
Google (Chrome)Believe WebRTC is good enough.
- There are some optimizations and improvements that are now finding their way into WebRTC in the browser
- But a lot of what is done now is kept out of the web and the open source community. WaveNetEQ is but an example of things to come
- It is their right to do that, but does this further the goal of WebRTC as a whole and the community around it?
Now that we’re heading towards differentiation, the larger vendors are going to invest in gutting WebRTC and improving it while keeping that effort to themselves.
No more level playing field.
Prepare for the future of WebRTCWhat I’ve outlined above is a potential future of WebRTC. One that is becoming more and more possible in my mind.
There’s a lot you can do today to take WebRTC and optimize around it. Making your application more scalable. Offering better media quality as well as use experience. Growing call sizes to hundreds or participants or more.
Investing in these areas is going to be important moving forward.
I’ve recently created a workshop covering the present and future of WebRTC, along with techniques and best practices employed by vendors in this space. If you want to learn more, you may want to take that workshop.
WebRTC Innovation and Differentiation in a Post Pandemic World
The post WebRTC unbundling: the beginning of the end for WebRTC? appeared first on BlogGeek.me.
WebRTC ports: Understanding IP addresses and port ranges in WebRTC
WebRTC IP addresses and port ranges can be a bit tricky for those unfamiliar enough with VoIP. I’d like to shed some light about this topic.
A recent back and forth discussion that I had with one of the people taking my online WebRTC course made it clear to me that there are still things I take for granted because I come with a VoIP heritage to what it is I am doing today. Which is why this article here.
Connecting a WebRTC session takes multiple network connections and messages taking place over different types of transport protocols. There are two reasons why that decision was made for WebRTC:
- There was a desire to have it run peer to peer, directly exchanging real time media between two browsers. This requires a different look at how to handle network entities such as NATs and firewalls
- Real time media is different from other data sent over the internet in browsers. The transport and signaling protocols already available were just not good enough to preserve high quality and low latency
Lets see how connections get made over the internet and how WebRTC makes use of that.
A quick explainer to internet connectionsWe will start by looking at the building blocks of digital communications – TCP and UDP.
The table below summarizes a bit the differences between the two:
TCP and UDP are two extremes of how transport protocols can be expressed TCP connectionsTCP is a reliable transport protocol. As such, it has a built-in retransmission mechanisms that is meant to make sure whatever is sent is received on the other end and in the same order of sending.
To do that properly, a TCP connection needs to be created. A TCP connection is a set of 4 values:
Source IP:Source port + Destination IP:Destination Port
How does one establish a TCP connection?
On your local machine you “bind” one of the local IP addresses of the machine to a local port number. That IP and port needs to be available and not taken for something else already. Then you need to try and connect to the destination IP:port.
Let’s say I want to connect to google.com.
For me, google.com resolves to the IP address 172.217.23.110. Assuming I want to connect to port 80 (a “randomly” picked port), I’d do the following: Bind a local IP:port (arbitrary local port), and connect it to 172.217.23.110:80.
Knowing the IP:port on source and destination of the connection means knowing the connection – there cannot be two such connections. Once you bind a local port to connect it to a remote address over TCP, that port cannot be reused until the connection is closed and done with.
If I want to open another TCP connection from my machine to the same address, I will need to bind yet another port on my local address and connect it to the destination IP:port,
Obviously, there are some caveats and edge cases I am ignoring here, but for our needs, the above is enough of an explanation.
UDP “connections”Since UDP is connectionless, there’s no real connection with UDP. No context whatsoever.
To send a message over UDP, I need again the quad of values:
Source IP:Source port + Destination IP:Destination Port
But this time, there’s no real connection. What happens here is that I open a local IP:port, and whenever I want to send out a message, I just tell it the destination IP:port and be done with it.
WebRTC signaling connections and addressesWebRTC signaling is just like any other web application connection.
In order to send and receive the SDP blobs to make the connection, I need to be able to communicate between the browsers and that is done using traditional networking means available in the browser: either HTTP or WebSocket. Both (ignoring HTTP/3) are implemented on top of TCP.
What does that mean?
- When my browser connects to the signaling server, it connects to an HTTPS or a Secure Websocket address (because… security)
- The destination address will be whatever the DNS will resolve for the name of the server I connect to; and for the most part, this connection will be done towards port 443
- The local address will be whatever local address I have on my machine
- The local port will be an arbitrary local port that the operating system will allocate
The end result?
The signaling server has a static IP and port, while the client is “dynamic” in natureLocal ports are arbitrary (and ephemeral). Destination port is 443 (or whatever advertised by the server).
WebRTC media connections and addressesMedia in WebRTC gets connected via SRTP. Most of the time, that would happen over UDP, which is what we will focus on in this section.
In naive SRTP implementations from before the WebRTC era, each video call usually used 4 separate connections:
- RTP for sending voice data
- RTCP for sending the control of the voice data
- RTP for sending video data
- RTCP for sending the control of the video data
While WebRTC can support this kind of craziness, it also uses rtcp-mux and BUNDLE. These two effectively bring us down to a single connection for voice, video, media and its control.
What happens though is this –
- You create a peer connection
- Then you add media tracks to it, effectively instructing it on what it is about to send or receive (or at least what you want it to send or receive)
- WebRTC will then allocate and bind local IP addresses and ports to handle that traffic. As with outgoing TCP connections, the local ports are going to be arbitrary and ephemeral
- The allocated IP:port addresses are now going to be used in the SDP being negotiated. These will be used as the local candidates
Since these addresses and ports are local, there’s high probability that they will be blocked by firewalls for incoming traffic.
Media servers work in the exact same way. In most cases, the addresses that they will use will be public IP addresses, but the ports will be arbitrary. That’s because media servers usually prefer handling each incoming device separately, by receiving its traffic on a dedicated socket connected to a specific port.
STUN “connections” and addressesSince we’re all behind NATs with our private IP addresses, we need to know our public IP address so we can connect to others directly (peer-to-peer).
To do that, STUN is used. WebRTC will take the media local IP:port it created (in that section above), and use it to “connect” over UDP to a STUN server.
This is in concept somewhat similar to how our signaling works – the local IP address has an arbitrary port, while the remote IP:port is known – and configured in advance in our peer connection iceServers. My advice? Have that port be 443.
Why do we do all that with STUN? So that we create a pinhole through the NAT which will allocate for us a public IP address (and port). The STUN server will respond back with the IP address and port it saw, and we will publish that so that the other side will attempt reaching out to us on that public IP:port pair. If the NAT allows such binding, then we will have our session established.
The STUN server has a static IP and port, while the client (and NAT) operate with “dynamic” IP addresses and portsThe above shows how Google’s STUN server works from my machine in AppRTC:
- My private address was 192.168.1.100:57086
- The STUN address in the iceServers was 108.177.15.127:19302 (the 19302 is the static port Google decided to use – go figure)
- My public IP address as was allocated by the NAT was 176.231.64.35:57086 (it managed to maintain and mirror my internal arbitrary port, which might not always be the case). This is the address that will get shared with the other participant of the session
With TURN, the server is relaying our media towards the other user. For that to happen, my browser needed to:
- Connect to a TURN server
- Ask the TURN server to allocate an address for the relay (and let me know what that address is)
- Use that address for incoming and outgoing traffic for the remote participant of the session
The above shows how Google’s TURN server works from my machine in AppRTC:
- My private IP for this session was 192.168.1.100:57086 (it was a different port, but I was too lazy to look it up, so bear with me)
- The STUN address in the iceServers was 108.177.15.127:19305 (as with STUN, the 19305 is the static port Google decided to use – still not sure why)
- The TURN server replied back with an allocation address of 108.177.15.86:28798. This was then placed as my ICE candidate. If the remote participant were to send media towards that address, the TURN server would forward that data to me
UDP, TCP and TLS work similarly in TURN when it comes to address and port allocation. What is important to notice here is how the TURN server opens up and allocates ports on the its public IP address whenever someone tries to connect through it.
Understanding port ranges in WebRTC configurationsWebRTC makes use of a range of addresses, ports and transport protocols. Far more than anything else that we run in our browsers. As such, it can be quite complex to grasp. There is order and logic in this chaos – this isn’t something inflicted on you because someone wanted to be mean.
In WebRTC the addresses and ports that get allocated by the end devices (=browsers), media servers and TURN servers are dynamic. This means that in many cases we have to deal with port ranges.
Go to any voice or video conferencing service running over the Internet. Search for their address and port configuration. They all have that information in their knowledgebase. A list of addresses and ports you need to open in your firewalls, written nicely on a page so that the IT guy will be able to copy it to his firewall rules.
Should these ranges be large? As in 49,152 to 65,535? Should this range be squeezed down maybe?
I’ve seen vendors creating a port range of 10 or 100 ports. That’s usually too little to run in scale when the time comes. I’d go with a range of 10,000 ports or more. I’d probably also try first to estimate the capacity of the machine in question and figure out if more ports might be needed to maintain the sessions per second I am planning on supporting (allocated TCP ports take some time to clear up).
Is this “wholesale” port range a real security threat or just an imaginary one? How do you go about explaining the need to customers who like their networks all clamped down and closed?
–
If you are looking to learn more about WebRTC, check out my WebRTC training courses. In the near future, I will start working on a new course about TURN installation and configuration – if you are interested in early access – do let me know.
The post WebRTC ports: Understanding IP addresses and port ranges in WebRTC appeared first on BlogGeek.me.
WebRTC TURN: Why you NEED it and when you DON’T need it
WebRTC TURN servers are an essential piece of almost any WebRTC deployment. If you aren’t using them, then make sure you have a VERY good reason.
Connecting a WebRTC session is an orchestrated effort done with the assistance of multiple WebRTC servers. The NAT traversal servers in WebRTC are in charge of making sure the media gets properly connected. These servers are STUN and TURN.
3 ways to connect WebRTC sessionsWhen connecting a session between two browsers (peer-to-peer) in WebRTC, there are 3 different alternatives that might happen.
Connect directly, across the local network Connecting WebRTC over a local networkIf both devices are on the local network, then there’s no special effort needed to be done to get them connected to each other. If one device has the local IP address of the other device, then they can communicate with each other directly.
Most of the time and for most use cases, this is NOT going to be the case.
Connect directly, over the internet, with public IP addresses Connecting WebRTC directly using public IP address obtained via STUNWhen the devices aren’t inside the same local network, then the way to reach each other can only be done through public IP addresses. Since our devices don’t know their public IP addresses, they need to ask for it first.
This is where STUN comes in. It enables the devices to ask a STUN server “what is my public IP address?”
Assuming all is well, and there are no other blocking factors, then the public IP address is enough to get the devices to connect to each other. Common lore indicates that around 80% of all connections can be resolved by either using the local IP address or by use of STUN and public IP addresses.
Route the media through a WebRTC TURN server Connecting WebRTC by using TURN to relay the mediaKnowing the public IP address is great, but it might not be enough.
There are multiple reasons for this, one of them being that the NAT and firewall devices in use are not allowing such direct traffic to take place. In such cases, we route the data through an intermediary public server called TURN.
Since we are routing the data, it is an expensive endeavor compared to the other approaches – it has bandwidth costs associated with it and it is why you Google won’t ever offer a free TURN server.
Transport protocols and WebRTC TURN serversTURN comes in 3 different flavors in WebRTC (6 if you want to be more accurate).
How testRTC checks and explains connectivity alternatives of TURN servers in qualityRTCYou can relay your WebRTC data over TURN by going either over IPv4 or IPv6, where IPv4 is the more popular choice.
Then there’s the choice of connecting over UDP, TCP or TLS.
UDP would work best here because WebRTC knows best when and how to manage network congestion and if to use retransmissions. Since it doesn’t always work, it might require the use of TCP or even TLS.
Which type of a connection would you end up with? You won’t really know until the connection gets established, so you’ll need to have all your options opened.
When is a TURN server needed in WebRTC?That’s easy. Whenever there can’t be a direct connection between the two devices.
For peer to peer, you will need to install and run a TURN server.
Try direct, then TURN/UDP, then TURN/TCP and finally TURN/TLSThe illustration above shows our “priorities” in how we’d like a session to connect in a peer to peer scenario.
If you are connecting your devices to a media server (be it an SFU for group calling or any other type of a server), you’ll still need a TURN server.
Why? Because some firewalls block certain types of traffic. Many just block UDP. Some may even block TCP.
With a typical WebRTC media server, my suggestion is to configure TURN/TCP and TURN/TLS transports and remove the TURN/UDP option – since you have direct access to the public IP address of the media server, there’s no point in using TURN/UDP.
Try direct to server, then TURN/TCP and finally TURN/TLSThe illustration above shows our “priorities” in how we’d like a session to connect with a media server.
What about ICE-TCP?There’s a mechanism called ICE-TCP that can be used in WebRTC. In essence, it enables a media server to provide in the SDP a ICE candidate using a TCP transport. This means the media server will actively wait on a TCP port for an incoming connection from the device.
It used to be a Chrome feature, but now it is available in all web browsers that support WebRTC.
This makes the use of TURN/TCP unnecessary, but will still leave us with the need of TURN/TLS.
Try direct UDP to server, then direct ICE-TCP to server and finally TURN/TLSThe illustration above shows our “priorities” in how we’d like a session to connect with ICE-TCP turned on.
The elusive (mis)configuration of TURN servers in WebRTCConfiguring TURN servers in WebRTC isn’t an easy task. The reason isn’t that this is rocket science. It is more due to the fact that checking a configuration to ensure it works properly isn’t that simple.
We are used to testing things locally. Right?
Here’s the challenge – in WebRTC, trying it on your machine, or with your machine and the one next to it – will ALWAYS WORK. Why? Because they connect directly, across the local network. This means TURN isn’t even necessary or used in such a case. So you never test that path in your code/configuration.
What can you do about it?
- Be aware of this
- Use the sample provided by Google for Trickle ICE testing. It won’t check everything, but it will validate that you’ve at least installed and configured the TURN server semi-properly
- Block UDP on the machine in your local network and then try to connect a session to another machine on your local network. Make sure it went over TURN/TCP relay (check webrtc-internals dump for that)
The above things can be done locally and repeatedly, so start there. Once you get this to work, move towards the internet to check it there.
Quick facts Do you need a TURN server if you connect your sessions to a WebRTC media server?Yes. WebRTC media servers don’t support TLS type of transport. Sometimes they do support TCP via ICE-TCP. For the cases where calls can’t connect in other ways, you will need to use TURN/TCP or TURN/TLS.
Do media servers need to have WebRTC TURN server configuration?Usually not. In most cases you will be installing media servers with direct internet access on a public IP address. This means that having TURN configured only on the WebRTC client side is enough.
How do you test a TURN server configuration for your application?An easy way is to block UDP traffic and see if your WebRTC client can still connect. Another one is to use Google’s Trickle ICE sample.
The post WebRTC TURN: Why you NEED it and when you DON’T need it appeared first on BlogGeek.me.
Announcing: WebRTC fiddle of the month
Once a month, I will be publishing along with Philipp Hancke a WebRTC fiddle of the month as a free lesson in my WebRTC Codelab. This continues an old tradition of Mozilla’s Jan-Ivar, the fiddle ot the week.
Time for a new experiment. If all goes well, we will be making it a monthly thing.
Somehow, a week or two ago, we came to the conclusion that it would be nice to do a short video explainer of something that people are trying to figure out with WebRTC.
To make this happen, we decide together what to do the short lesson about, then Philipp Hancke writes a jsFiddle piece of code to implement it. And then we sit and record the explanation of it, creating a new free lesson in our joint WebRTC Codelab course.
What does each WebRTC fiddle of the month include?Each WebRTC fiddle of the month has these 3 resources:
- A short video explaining the problem and how we solved it
- The link to the jsFiddle code
- Transcription of the video
Creating the WebRTC Codelab was fun. We’re thinking of recording a new course at some point, but until we wrap our heads around that one, we’ve decided to continue recording some more lessons.
Seems like we work good together, so finding yet another excuse to do something made enough sense.
Oh, and if you happen to decide that you need to learn more about WebRTC, and end up enrolling to our course, then that’s a definite win
Two requests I have for you #1 – Check our first “fiddle of the month”Our first explainer fiddle is about creating a peer connection that includes screen sharing and an audio microphone stream wrapped nicely together. You might get zoom-fatigue (or the WebRTC equivalent of that term), but you almost always want to talk when trying to screen share and collaborate.
Go watch our fiddle – Sharing screen + microphone together
Future WebRTC fiddles won’t be announced here, but only on social media and in the WebRTC Weekly (so subscribe to it). These fiddles will all be available in the WebRTC fiddle of the month section of the WebRTC Codelab course.
#2 – Suggest some more ideas for such fiddlesGot ideas or requests for fiddles?
I can’t promise we will record your request, but I can promise you we will seriously think about it once we sit down to decide what to record.
Just contact me and tell me what you think.
The post Announcing: WebRTC fiddle of the month appeared first on BlogGeek.me.
WebRTC browser support on desktop and mobile
2020 offers an interesting viewpoint to WebRTC browser support. Where exactly is it available in desktop and mobile, and what can you do about it as a developer?
This is almost a yearly article that I now write, each time with a slightly different focus to it. We’re now halfway into 2020, and things are changing fast.
Here’s a quote that I am seeing a lot this year:
Sometimes this quote is quite literally true. pic.twitter.com/SkVooF9Fez
— The Long Now Foundation (@longnow) January 1, 2020It rings true for the last few weeks when it comes to WebRTC, but somehow, in the domain of WebRTC browser support, we’re still standing in place.
My most up to date slide on WebRTC browser support?
We will get back to it in detail a bit later.
For now I’d like to look at the “Can I use” website, filtered for WebRTC. It gives a good starting point (although somewhat misleading). I will use that as the basis of looking at WebRTC on desktop and mobile.
WebRTC support on desktopOn the desktop today, all modern web browsers support WebRTC.
This has been the case for quite some time now. I’ve announced that this means that WebRTC is ready towards the end of 2018.
Why?
Because the consumption model in the desktop today is done through web applications, while on mobile, it is predominantly based on native applications. So the moment all desktop browsers are nicely represented and supported, things look bright.
This isn’t to say that there aren’t challenges with WebRTC browser support – obviously there are.
I can list a few of them here out of the top of my head:
- No support in Internet Explorer (and there won’t be any for this dying browser)
- Edge still has its old version and the new Chromium based one. They behave differently, with the new Chromium one acting just like Chrome for anything WebRTC related
- Safari still suffers from its need to differentiate by not doing what other browsers are doing. It has no VP9 support, and it is still somewhat buggier than the rest of the crowd
- Things like hardware acceleration support and proper rendering, antivirus CPU issues and CPU consumption in general still plague the main implementation (=Chrome) today
When it comes to mobile, support for WebRTC is a bit more complicated.
WebRTC iOS Safari support Is WebRTC really available on iOS Safari?iOS Safari has been supporting WebRTC since Safari 11.
We’re now in Safari 13.5 and things are still rather grim when it comes to true support of WebRTC.
iOS Safari WebRTC is such a broken mess that my going suggestion to clients unfortunately is to not support it and redirect users to a native app installation. I had to manually go through all open WebRTC bugs in webkit to figure out how to explain this to my clients and help them in reaching that conclusion and even conveying that to their customers.
There are nasty bugs in iOS Safari that have been opened since 2019 or earlier relating to media handling of WebRTC. These aren’t just edge cases, but rather things you’ll have users bump into in regular use. Some of them have finally been fixed in the latest 13.5.5 beta earlier this month.
Oh – and if you plan on using any OTHER browser on iOS then WebRTC won’t be supported there. Why? Because Apple hasn’t made WebRTC available in its Webkit Webview on iOS and they aren’t allowing anyone to build a mobile iOS browser that doesn’t use Webkit as its rendering engine. So much for freedom and choice.
Up until now, there was no serious way to run a WebRTC web application in iOS Safari in production at scale. Hopefully, this is now mostly solved…
Android browsers support for WebRTC How well is WebRTC supported in the fragmented Android world?Android has its own set of headaches when it comes to WebRTC. That’s because there’s no single Android out there, but rather a slew of them.
Here’s what we can glean from a close look at that “can I use” list above.
- Android Browser, Chrome for Android and Firefox for Android are the gold standard. If these are what your browsers “bump” into, then you’re in good shape
- Opera… it depends. Opera Mobile is just fine. Opera Mini doesn’t support WebRTC
- UC Browser for Android has no WebRTC support
- Samsung Internet, quite the popular option you may run into, has WebRTC, but requires a webkit prefix. What does this mean? That it probably runs an old version of the WebRTC implementation, never a good thing with WebRTC
- QQ Browser and Baidu Browser, both the China alternatives to Chrome also have WebRTC support but also with a webkit prefix. Support there would also be tricky for web applications without some serious regression testing
While WebRTC is nicely supported in Android, it is going to be hard sometimes to decide what that support exactly means. Knowing that is a mix of understanding the device and the browser the web application is being executed on top.
Where do we go from here?If you read everything until here, then understand this: WebRTC is a work in progress.
It is the best (and only) alternative you have for real time communications that works in the browser without any installation. It works well enough for large companies to release applications (web and native) that attract massive user bases.
As with many other technologies, starting to use it is simple. Getting it to a professional level requires a lot more investment and commitment.
–
Next week I’ll be starting off my “future of WebRTC” workshop. This workshop is going to cover many aspects of the changing landscape of WebRTC. I’ll be touching issues of infrastructure, optimization and differentiation. All with a view of the current best practices as well as the latest trends.
There are 2-3 more seats available in the workshop. If you are interested in joining, check here.
The post WebRTC browser support on desktop and mobile appeared first on BlogGeek.me.